Understanding Kafka’s auto offset reset configuration: Use cases and pitfalls
The auto.offset.reset configuration defines how Kafka consumers should behave when no initial committed offsets are available for the partitions assigned to them. Learn how to work with this configuration and discover its related challenges.
-
Learn to process streaming data!
Quix Streams is a fast and general-purpose processing framework for streaming data. Build real-time applications and analytics systems on data streams using Python DataFrames and stateful operators, all without having to install a server-side engine.
Introduction
Due to its scalability, high performance, reliability and rich ecosystem, Apache Kafka has become the de facto standard for anyone working with streaming data. Thousands of developers and organizations worldwide rely on Kafka to ingest, process and derive value from real-time data.
And, although it brings plenty of benefits, Kafka is a very complex distributed system. Contributing to this complexity is the fact that Kafka has hundreds of configuration options, some of which are difficult to understand and even harder to master.
In this article, I zoom in on one of Kafka’s trickiest configurations — "auto.offset.reset" , which determines how a consumer behaves when reading from a topic partition when there is no initial offset. I will look at how "auto.offset.reset" works, explore its use cases and highlight its pitfalls.
Why do Kafka offsets matter and how do they relate to partitions and
consumer groups?
Before we dive into Kafka’s "auto.offset.reset" setting, let’s start by giving a quick overview of topics and partitions and how consumer offsets relate to them.
In most circumstances, you can handwave the concept of topics away as simply “a thing that stores messages”. However, when it comes to understanding how message consumption actually works, we need to dive one layer deeper.
A topic consists of partitions; the amount of partitions for any given topic is specified when you create said topic. Partitioning enables parallel processing for consumer groups — when you assign multiple consumers (in the same group) to the same topic, the partitions are split across them (each consumer has an assigned partition).
You can think of topic partitions as files that have messages endlessly appended to them as producers publish them. The Kafka broker that owns a partition assigns an offset (integer) to each message. This offset is simply the next number in the sequence for that partition — the first message in a partition has an offset of 0, the second message has an offset of 1 and so on.
Each consumer group then keeps track of what messages it has already read (and thus what should be consumed next) by storing the last offset it successfully committed, independently for each topic partition, as part of its own group metadata. This way, if a consumer in the group crashes or restarts (or if a rebalancing takes place), the consumer knows where to resume reading from when it’s operational again.
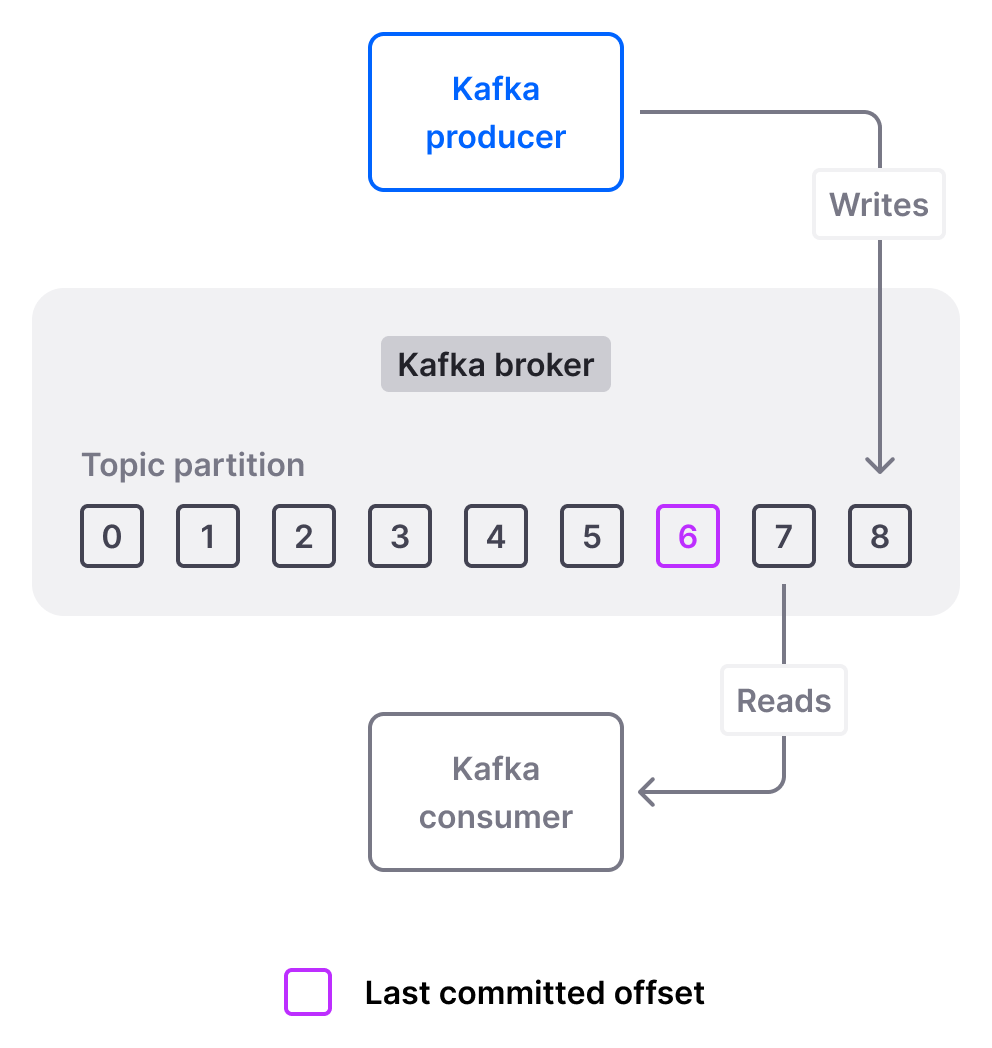
The key takeaway? Try to think of a topic as a human-friendly collection of partitions — each with its own offsets, which are referenced by consumer groups to track their own message consumption progress.
But what happens when you make a brand new consumer group, since new groups do not start with ANY stored partition offsets? Enter "auto.offset.reset".
The auto offset reset configuration
The "auto.offset.reset" configuration in Apache Kafka determines how a consumer group behaves when no initial committed consumer offset is available. This configuration is mostly applicable when a consumer group (usually a new one) reads from a topic for the very first time and the consumer instances within the group need to know exactly where to start reading from the topic’s partitions. Additionally, "auto.offset.reset" is handy in scenarios where the last committed offset no longer exists (i.e., it was deleted due to the retention policy).
Note: Once a message is read by a consumer and the consumer commits the offset of the respective message, the "auto.offset.reset" configuration no longer applies, since there is now an offset that acts as a starting point going forward.
Per the Apache Kafka documentation, there are three acceptable values you can specify for the "auto.offset.reset" configuration parameter:
| Value | Description |
|---|---|
| earliest | Automatically reset the offset to the earliest offset. |
| latest | Automatically reset the offset to the latest offset. This is the default value. |
| none | Throws an exception to the consumer if no previous offset is found for the consumer's group. This value is fairly uncommon and infrequently used, as it serves very specific edge use cases. |
The way in which the Kafka documentation describes these values is a bit vague and perhaps even confusing, so let’s explain them more clearly.
Setting "auto.offset.reset" to "earliest" instructs consumers to begin reading from the earliest available offset in each topic partition. In other words, consumers will process messages from the very beginning of the log.
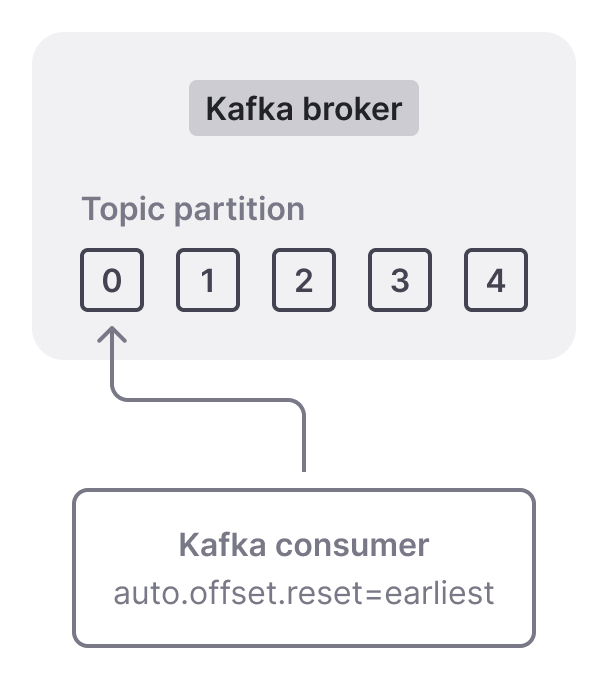
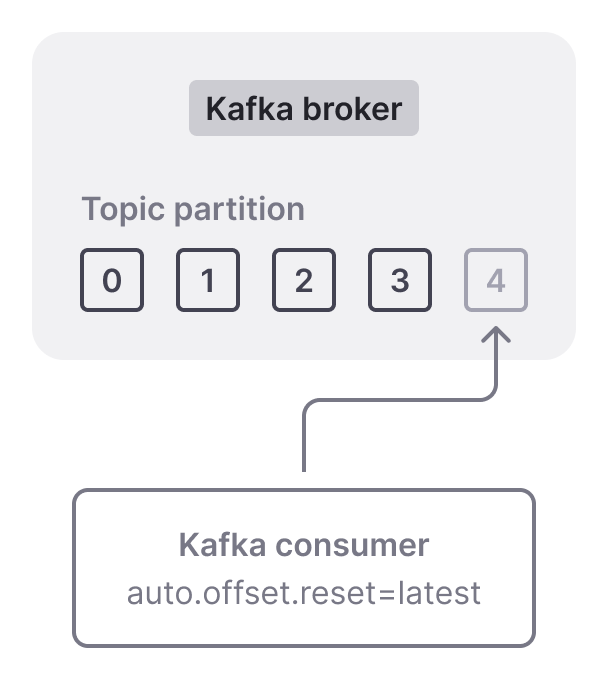
In contrast, with "auto.offset.reset" set to "latest" (which is the default), consumers will ignore previously published messages. Instead, they will wait for and consume only new messages. For example, in the following diagram, we can see 4 messages already published to a partition (offsets 0-3). Since "auto.offset.reset" is configured to "latest" , the consumer ignores the existing messages and will start consuming from the message with offset 4 (which is not yet published).
Finally, when using the "none" option, if a consumer instance encounters a situation where there is no valid committed offset, it will throw an exception. This means the code implementing the Kafka consumer logic is responsible for catching and managing the exception. How the exception is handled (e.g., logging the error, sending an alert, manual intervention, reading from a particular offset) depends on the specific implementation and requirements of the application.
The "auto.offset.reset" configuration might seem pretty straightforward. But don’t let this apparent simplicity deceive you. Before selecting an "auto.offset.reset" approach it’s essential to gain a thorough understanding of your use case and whether your consumer application needs to process all available data or just new data.
We’ll now take a look at the recommended use cases for "auto.offset.reset=earliest" and "auto.offset.reset=latest" and highlight their pitfalls. Note that I won’t be talking about the "none" option. That’s because it’s rarely used in practice (as far as I know) and only suitable for edge use cases where you need to manually manage offsets.
Setting auto offset reset to "earliest": use cases and pitfalls
Setting the "auto.offset.reset" policy to "earliest" is the best option if you’re new to Kafka and data integrity is critical for your use case. That’s because "earliest" allows the consumer to read all available messages from the beginning of the partition log, greatly diminishing the risk of missing data and significantly reducing the need for you to manually intervene to handle skipped messages.
Having "auto.offset.reset=earliest" is a good choice especially if:
- You have newly created Kafka topics and consumer applications.
- You need to replay data, so you can build or reconstruct state. This is relevant when implementing the event sourcing pattern or when initializing a new service that requires a complete view of the data history.
However, "auto.offset.reset" set to "earliest" is not a silver bullet. This approach can be challenging if you have pre-existing topics with very large backlogs. Reprocessing huge volumes of data can increase operational costs and strain system resources, leading to performance degradation, higher latency, instability and potential bottlenecks in data pipelines.
Additionally, since reading from the earliest offset might lead to reprocessing messages, ensuring your ecosystem handles duplicate messages gracefully (i.e., idempotent processing) is critical.
If you plan to use "auto.offset.reset=earliest" you also need to give some serious thought to your topic retention policy, which directly impacts what messages will be available for consumers to read. Here are a couple of points to consider:
- If your topic's retention period is relatively short, older messages may be deleted before your consumer has a chance to read them, especially if the consumer is offline for some time or is processing data slower than the rate of data expiration.
- A longer retention period might be necessary to ensure data is available when needed, but this also requires more disk space.
Setting auto offset reset to "latest": use cases and pitfalls
Setting "auto.offset.reset" to "latest" is a common approach for developers and organizations with already established topics and/or architectures. It’s the best option if you only care about new messages being produced and don't need to process historical data.
However, it’s important to note that "auto.offset.reset=latest" behaves in a way that is not immediately apparent, which may lead to data integrity issues. Let’s look at a hypothetical scenario to showcase these issues. Imagine you have a partition with 5 existing messages (offsets 0-4) and you start a new consumer, with "auto.offset.reset" set to "latest". The consumer will ignore the existing 5 messages and only read new messages published by the upstream producer. Now let’s assume the producer publishes a new message (offset 5), but the consumer crashes before it’s able to process it and commit its offset.
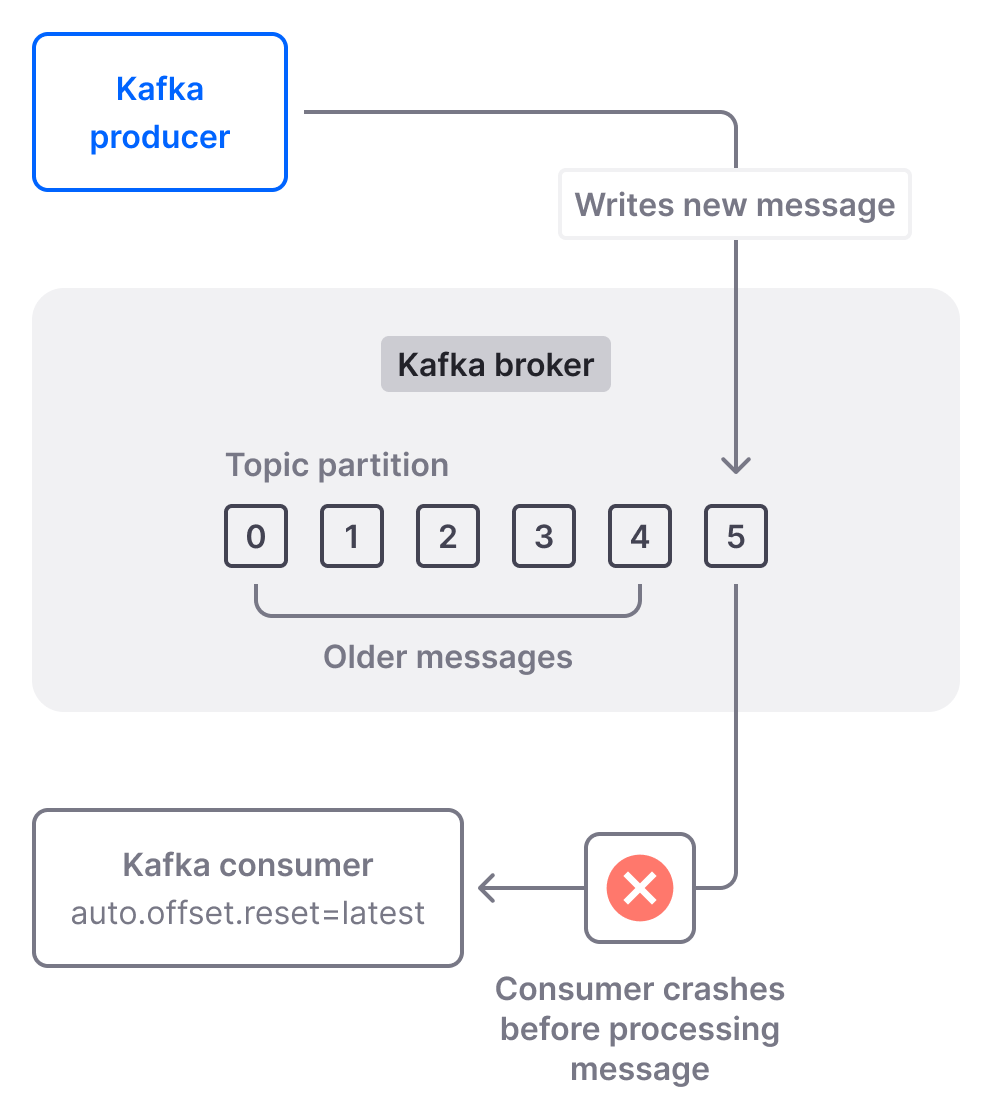
You restart the consumer (or assign a new consumer to the partition). But in the meantime, the producer has published several new messages (offsets 6-10). Since there is no committed offset available, when the consumer restarts (or a new one is initialized), "auto.offset.reset" set to "latest" is still active. So what happens now? The consumer will wait for new messages (starting with offset 11) to be published before reading from the partition, while messages with offsets 5-10 will never be processed.
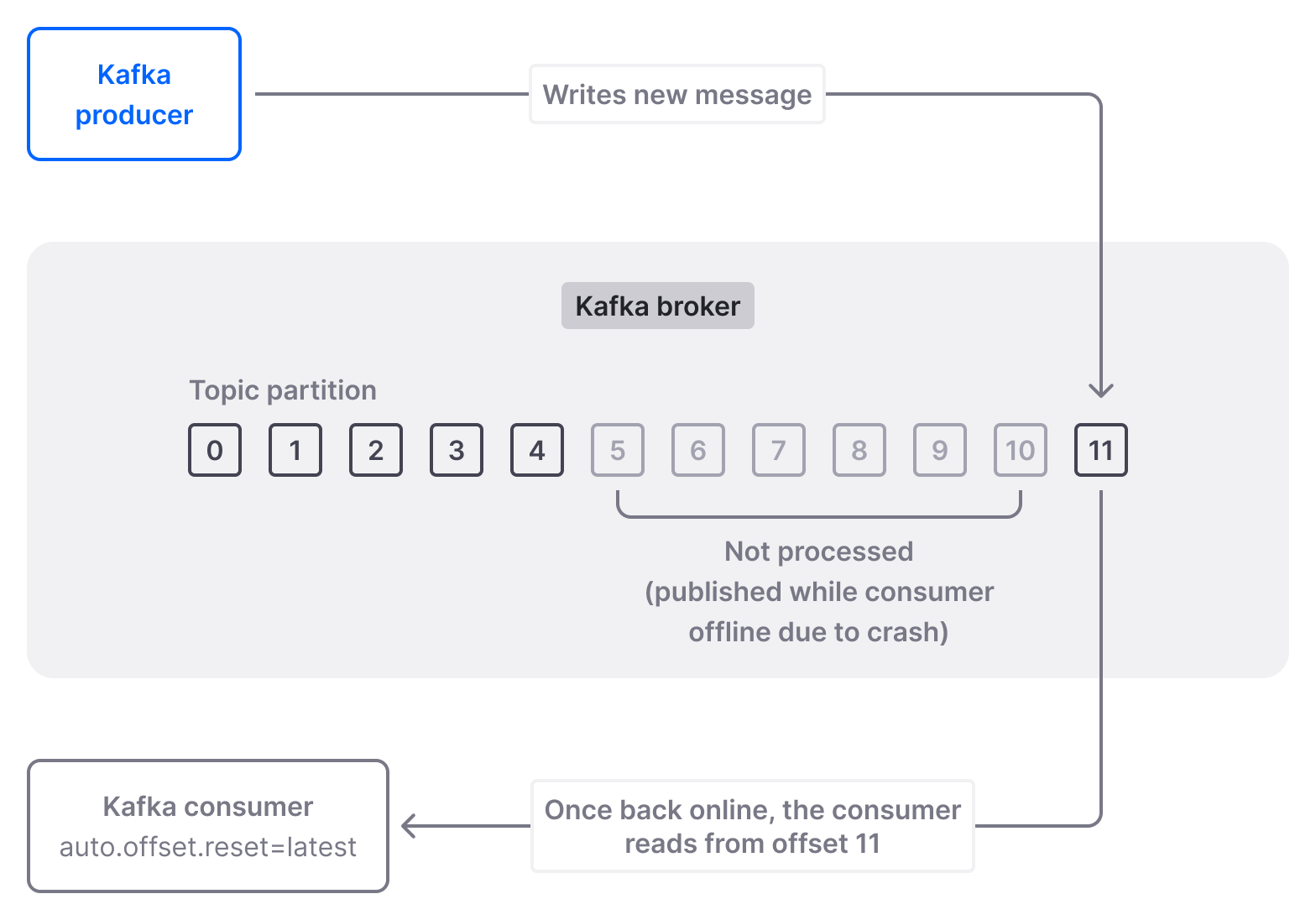
This is a deal-breaker if your application relies on no new messages being skipped.
The LotusFlare engineering team had a similar experience with "auto.offset.reset" set to "latest". At one point, the team encountered a scenario where the rate of data consumption from certain topics lagged significantly behind the message production rate. This discrepancy, coupled with "auto.offset.reset=latest" and a sub-optimal data retention policy almost resulted in substantial data loss. The LotusFlare team ultimately recovered the lost data (since the data source lived in a persistence layer in their stack). They also ended up making some changes to their Kafka setup in case they had to deal with similar situations in the future:
- Extended data retention policy to provide more wiggle room for systems to restabilize.
- Updated Kafka "auto.offset.reset" policy to "earliest" in several applications to “reduce the blast radius associated with data loss by attempting to load the oldest available record in Kafka”.
Conclusion
Although it might seem straightforward at first, "auto.offset.reset" is arguably one of the most difficult Kafka consumer configurations to master. After reading this article, you hopefully have a good understanding of what"auto.offset.reset" does, how it works and what its pitfalls are.
Efficiently dealing with "auto.offset.reset" is just one of the many challenges of managing Kafka. However, despite being an intricate tool, Kafka is worth the complexity.
If you want to benefit from Kafka while avoiding some of its complexity, check out Quix, a complete platform for building, deploying and monitoring streaming data pipelines. First, we have Quix Streams, an open source Python library for building containerized stream processing applications with Kafka. Wrapping Quix Streams is Quix Cloud, a serverless CaaS (Container-as-a-Service) platform that provides fully managed containers, Kafka and observability tools. To learn more about Quix and what it can do for you, see it in action and explore the official documentation.
Check out the repo
Our Python client library is open source, and brings DataFrames and the Python ecosystem to stream processing.