.svg)
MATLAB runner reference architecture
How many times have your R&D teams run the same MATLAB simulation with slightly different parameters, only to lose track of which version produced the breakthrough results? If you're managing complex electro-mechanical systems development, whether it's optimizing thermal management, validating control algorithms, or fine-tuning performance, this scenario probably hits close to home.
The MATLAB Runner Reference Architecture addresses this exact challenge by creating a centralized, automated pipeline that captures every simulation run, tracks parameter variations, and stores results in a queryable format. Instead of sifting through scattered desktop files or trying to recreate that "one perfect run" from three months ago, your teams can focus on engineering innovation.
About the reference architecture
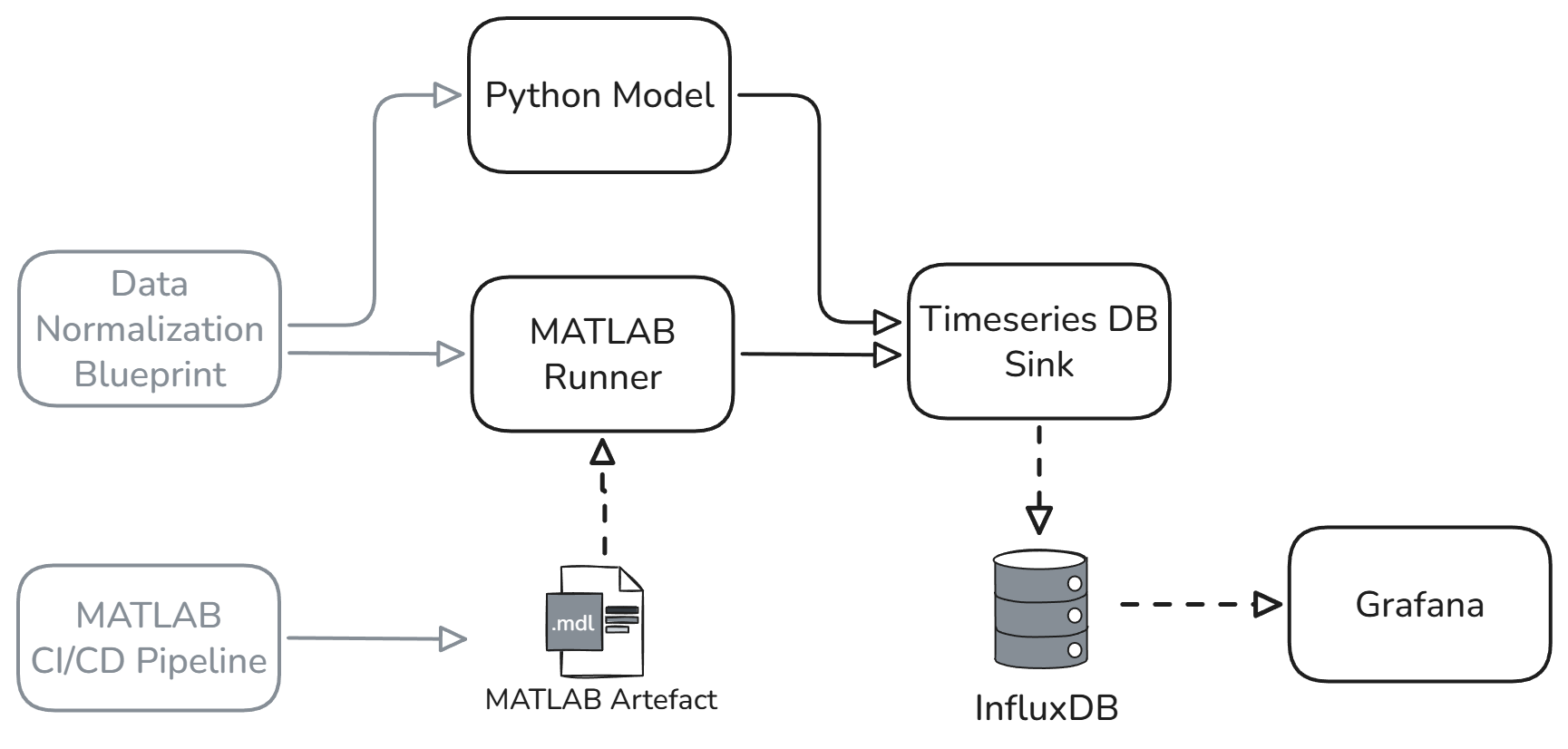
This reference architecture provides a complete data processing pipeline specifically designed for organizations running MATLAB simulations at scale. It automatically captures simulation artifacts, normalizes data formats, executes models with proper versioning, and stores results in a time-series database for immediate analysis and long-term reference.
The pipeline consists of several core components working in harmony. The Data Normalization Blueprint standardizes incoming data formats from various sources. The MATLAB Runner executes simulations with proper parameter tracking. The Python Model component executes any Python models. Finally, the Timeseries DB Sink stores all results in an easy access DB and we’ve integrated Grafana dashboards for real-time visualization.
Turn simulation chaos into success
R&D teams running MATLAB simulations face a frustrating paradox. The more successful your simulation programs become, the harder they are to manage. Your control team might run 200 parameter sweeps in a week, each generating gigabytes of telemetry data. Your HVAC optimization engineers could be testing thermal models with dozens of variables across multiple building scenarios.
Typically, each simulation run creates files scattered across individual workstations. Engineers save results with inconsistent naming conventions. Parameter configurations get buried in code comments or, worse, exist only in someone's memory. When you need to compare results from six months ago with today's data, you're essentially conducting an archaeological dig through folder structures that make sense only to their original creators.
The situation becomes more painful when deadlines approach. You don’t want to be hunting for proof that a system works under specific conditions just as the auditors arrive only to find that “final_final_v3.txt” was deleted accidentally.
Senior software engineers know this isn't sustainable, but they're caught between competing demands. They need to support multiple R&D teams, each with their own MATLAB workflows, while maintaining data integrity and enabling collaboration. They're often working with limited resources, trying to build data infrastructure that can handle terabytes of simulation data without breaking the bank or overwhelming their existing IT systems.
Building a centralized simulation management system
The MATLAB Runner Reference Architecture transforms the chaotic simulation management scenarios described above into a streamlined, automated process that captures every detail while staying out of the engineers' way.
When an engineer commits a MATLAB model to version control, the CI/CD pipeline should automatically validate the code, run regression tests, and prepare it for execution. No more wondering if the latest changes broke something else. The MATLAB Runner component is triggered and executes simulations with full parameter logging, automatically capturing input configurations, execution metadata, and performance metrics alongside the actual results.
What makes this architecture particularly powerful for R&D environments is that it doesn't force your teams to abandon their existing MATLAB workflows. Engineers continue developing models the way they always have done. The pipeline simply captures everything that happens, creating a complete audit trail without disrupting creative processes.
The Data Normalization Blueprint ensures that whether your simulation outputs voltage measurements from battery tests, pressure readings from HVAC systems, or acceleration data from drone flights, everything gets standardized into consistent formats. This means your thermal engineers can easily compare their HVAC optimization results with historical data, even if the original simulations used different output schemas. Read more about the Data normalization blueprint here.
If you have other, non MATLAB models they can be run from the Python Model component. It's designed to run a variety of pretrained models, enabling additional options for software developers to support R&D engineers. The insights from both types are standardized and become available to the broader team within minutes.
All results flow into a time-series database optimized for the kind of numerical data that MATLAB simulations generate. This is intelligent storage that understands the temporal nature of your data and optimizes queries accordingly. Engineers can query results by time ranges, parameter values, or simulation versions using familiar SQL-like syntax.
Key features of this reference architecture
Automated simulation orchestration forms the backbone of this architecture. The MATLAB Runner doesn't just execute your models, it manages the entire simulation lifecycle. It tracks which version of your model ran, with which parameters, at what time and how much computational resources were consumed. This means you can automatically correlate performance results with the specific model version and parameter set that generated them.
Seamless version control integration ensures your simulation models follow the same rigorous practices as your production software. Every change gets tracked, every execution gets linked to a specific commit, and every result can be traced back to its exact source code. You can immediately identify which simulation run predicted a behavior and trace it back to the exact code changes.
Time-series optimized storage understands that R&D data is fundamentally different from business metrics. Your simulation results have natural time relationships: input parameters at T0, intermediate calculations at T1, T2, T3, and final results at Tn. The storage is optimized for retrieval for these patterns, making it fast to query results across time ranges or parameter sweeps.
Integrated visualization through Grafana provides immediate visual feedback on simulation results. Engineers can create complex dashboards that aren't just static reports, they're interactive tools that update automatically as new simulations complete.
Code sample
Here's how the MATLAB Runner component handles simulation execution and result capture:
import subprocess
import json
import logging
from datetime import datetime
from quix_streams import Application
from influxdb_client import InfluxDBClient, Point
class MATLABRunner:
def __init__(self, app: Application):
self.app = app
self.results_topic = app.topic("simulation_results")
def execute_simulation(self, model_path, parameters, version_hash):
"""Execute MATLAB simulation with full tracking"""
# Prepare execution metadata
execution_id = f"sim_{datetime.now().strftime('%Y%m%d_%H%M%S')}_{version_hash[:8]}"
start_time = datetime.now()
logging.info(f"Starting simulation {execution_id}")
# Build MATLAB command with parameter injection
matlab_cmd = [
'matlab', '-batch',
f"run('{model_path}');",
f"save('results_{execution_id}.mat', 'results', 'metadata');"
]
# Execute simulation
try:
result = subprocess.run(matlab_cmd, capture_output=True, text=True)
end_time = datetime.now()
execution_time = (end_time - start_time).total_seconds()
# Process results
if result.returncode == 0:
self.publish_results(execution_id, parameters, execution_time, version_hash)
logging.info(f"Simulation {execution_id} completed successfully")
else:
logging.error(f"Simulation {execution_id} failed: {result.stderr}")
except Exception as e:
logging.error(f"Failed to execute simulation: {str(e)}")
def publish_results(self, execution_id, parameters, execution_time, version_hash):
"""Publish results to streaming pipeline"""
with self.results_topic.get_producer() as producer:
result_data = {
"execution_id": execution_id,
"timestamp": datetime.now().isoformat(),
"parameters": parameters,
"execution_time_seconds": execution_time,
"model_version": version_hash,
"status": "completed"
}
producer.produce(
key=execution_id,
value=json.dumps(result_data)
)This code sample demonstrates how the MATLAB Runner captures comprehensive metadata for every simulation execution. The execution_id creates a unique identifier linking results back to specific parameter sets and model versions. The subprocess execution safely runs MATLAB while capturing both success and failure scenarios. Most importantly, all results immediately flow into a Kafka topic then into the rest of the pipeline where they can be processed, analyzed, and then stored without manual intervention.
Systematic R&D infrastructure
The MATLAB Runner Reference Architecture solves a fundamental challenge of simulation management in modern R&D environments: how to maintain the creative flexibility your engineers need while building the data infrastructure your organization requires.
Your research teams can continue developing models in MATLAB while automatically capturing every parameter sweep and result. Your R&D engineers can run optimization simulations knowing that all data gets properly versioned and stored for future reference. You can have the confidence that every test scenario is documented and reproducible.
This is an architecture that scales with your needs. Whether you're running ten simulations per week or ten thousand, the pipeline handles execution, data capture, and storage automatically. Your senior software engineers get the centralized data management they need to support multiple R&D teams. Your senior R&D leaders get the traceability and reproducibility required for certification and compliance.
Most importantly, this reference architecture eliminates the painful bottlenecks that slow down innovation. No more hunting for historical simulation data. No more recreating parameter configurations from memory. No more wondering which model version produced specific results.
Are you ready to transform your MATLAB simulation workflows into centralized, collaborative processes? The Quix Framework and the MATLAB Runner Reference Architecture provide the foundation your R&D teams need to move faster while maintaining the rigor that complex electro-mechanical systems demand. Explore how this architecture can adapt to your specific simulation requirements and start building the data infrastructure that will accelerate your next breakthrough.
Using this template
This blueprint can be useful for the following use cases:
• R&D
• Test Chamber
• Test Run
• Simulation
• Digital Twin
Main project components
Python Model runner
MATLAB runner
Timeseries DB
Grafana
Technologies used
