.svg)
Industry insights
Apr 24, 2026
Why infrastructure, not models, is driving industrial AI adoption
Industrial AI gains aren't coming from frontier LLMs, they're coming from traditional AI models. Better infrastructure is now making these models usable.


Most of the conversation about AI in industrial R&D right now is about frontier LLMs. But the productivity gains that are showing up in engineering organisations are still mostly coming from older forms of AI: statistical optimisation methods, surrogate modelling, and adaptive experiment selection. These techniques are not new. Many of the underlying ideas were studied decades ago and have been used in engineering contexts since at least the late 1990s.
What is newer is the surrounding infrastructure. For a long time, industrial AI adoption was limited less by the quality of the methods than by the difficulty of getting them into day-to-day engineering workflows. R&D teams found it difficult to access and unify the right data, to connect models to the systems that produced and consumed that data, and to find people who could bridge the gap between statistical methods and practical engineering work.
That is now starting to change. A new generation of software companies is making industrial AI easier to adopt by productising the infrastructure around it: data pipelines, orchestration layers, integration with existing toolchains, interfaces that hide modelling complexity, and service models that help engineering teams build repeatable workflows instead of one-off pilot projects. The result is that techniques which once worked only in flagship programmes, with specialist support and lengthy integration efforts, are becoming viable in a wider range of industrial R&D settings.
The most important shift is less about developing more effective AI models and more about laying the data and workflow foundations needed to make older methods usable at scale.
The “other” industrial AI
Despite all the current hype, the most important from industrial AI is still not the LLM-driven variety. It is a family of optimisation and modelling techniques built around iterative learning loops. A team generates a candidate experiment, runs it, updates a model with the result, and then uses that updated model to decide what to try next.
The model is usually a surrogate: a faster statistical approximation of the underlying system. The surrogate does not replace the physical engine, the wind tunnel, the CFD solver, the FEA model, or the battery test bench. It helps decide where to spend the next expensive evaluation. In that sense, its value is not that it makes engineering systems disappear, but that it reduces the number of costly runs needed to learn something useful.
This general pattern appears in several well-established engineering workflows. Design of Experiments is the classic example. If a system has many input variables, exhaustive testing quickly becomes infeasible, so engineers choose a subset of experiments that will still reveal which factors matter and how they interact. Classical DoE methods, such as factorial designs or Latin hypercube sampling, define that subset in advance. More adaptive approaches, including Bayesian optimization, update the design as new results arrive. If the first wave of tests shows that several variables are irrelevant, later iterations can stop spending effort on them. Knowledge from earlier campaigns can also be reused rather than discarded.
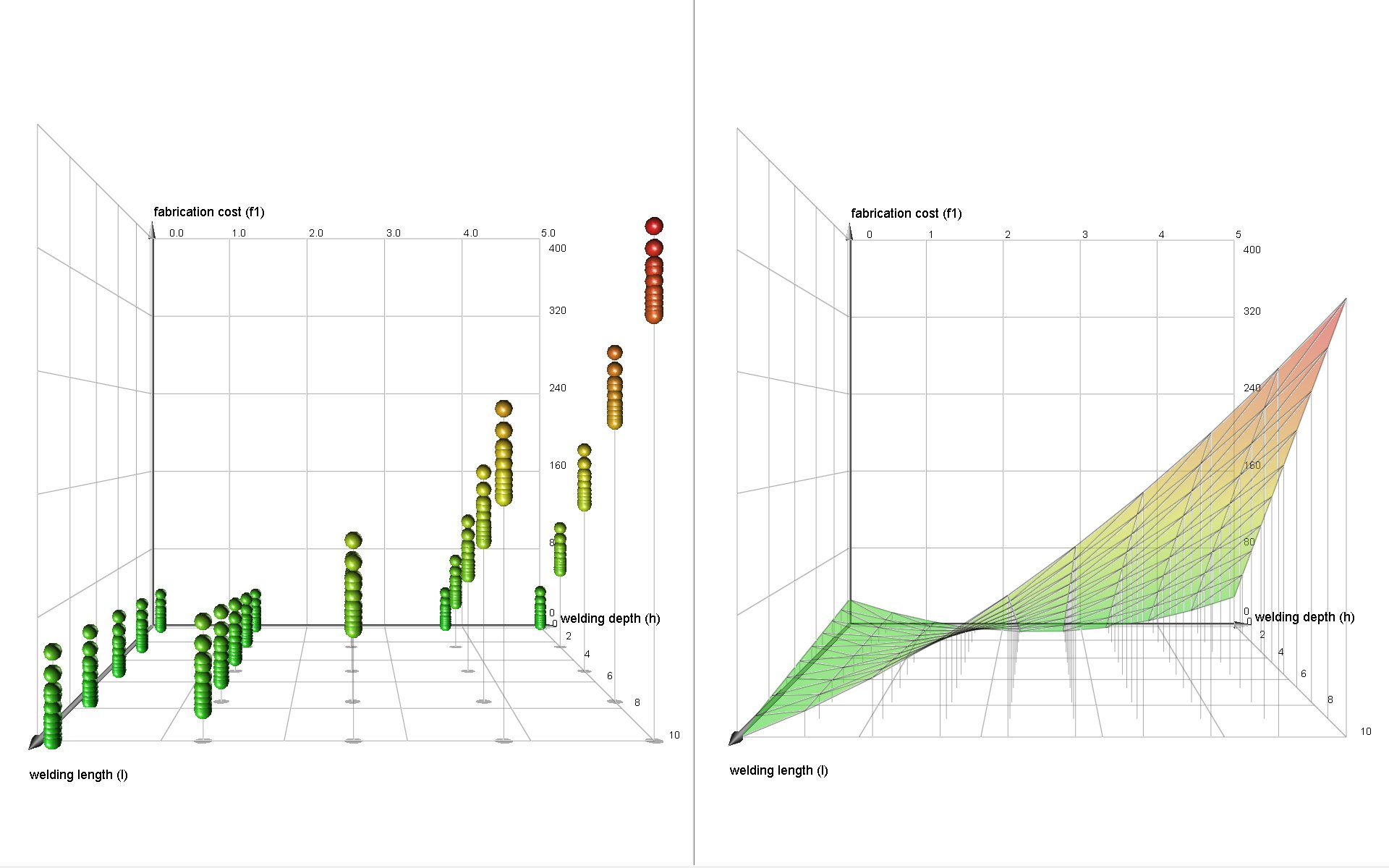
Simulation optimization applies the same logic to numerical models rather than physical experiments. An aerodynamicist exploring geometry variants in CFD or a structural engineer sweeping through material parameters in FEA is still navigating a large design space under cost constraints. In these settings, the workflow is comparatively tidy: the solver is already digital, inputs and outputs are in the same computational environment, and there is no sensor noise, dyno scheduling problem, or physical safety constraint to contend with. That relative neatness helps explain why this class of tooling was commercialised earlier. By the 2000s, products such as NUMECA FINE/Design3D, ESTECO modeFRONTIER, Siemens HEEDS, and Dassault Isight had already turned surrogate-based optimisation into a market category.
System calibration is another instance of the same basic loop, but one that proved much harder to automate. A calibration engineer working across engine maps or control parameters faces the same core challenge: the search space is too large to explore exhaustively, each test is expensive, and the team needs a way to propose promising next operating points while learning from previous results. In principle, surrogate-based methods fit this problem extremely well. In practice, calibration took much longer to move from research papers and internal prototypes into routine industrial use.
That contrast points to the real bottleneck. It wasn’t as if calibration engineers had now somehow been denied access to a sufficiently powerful model class. The bottleneck was simply that the surrounding workflow was messy, fragmented, and expensive to automate.
Why industrial AI was slow to take off
The main reason simulation optimization was commercialised earlier than physical-test applications is that simulation workflows already produce data in a relatively coherent form. A simulation campaign tends to generate its inputs, outputs, and metadata within a single digital environment. A physical test campaign does not.
In a typical calibration programme, data may arrive from test benches in LabVIEW TDMS files or proprietary DAQ formats. Each source can have its own schema, clock, sampling rate, and naming conventions. Results from earlier campaigns may be sitting in Excel spreadsheets, team databases, or local file shares. Calibration maps may be trapped inside specialist tools such as ETAS INCA or AVL CRETA. Even when each individual tool works perfectly well for its local purpose, the overall workflow is badly suited to closed-loop optimisation. Before any model can recommend the next experiment, someone has to unify all of this into a dataset that is coherent enough to learn from.
That integration burden was often heavier than the modelling work itself. A team could know, in theory, that Gaussian processes or other surrogate-based methods might reduce campaign size, but still be unable to test the idea without months of data engineering work.
The second barrier was expertise. The engineers who understood dyno sweeps, drive cycles, emissions constraints, and map convergence were usually not the same people who understood acquisition functions, uncertainty estimates, or kernel selection. The two groups used different vocabularies, different tools, and different assumptions about what counted as a sensible workflow. Bridging that divide meant either training rare hybrid specialists or embedding data scientists directly into engineering teams.
This is why many of the early successes in AI-enhanced calibration or adaptive DoE showed up in flagship programmes. They worked, but they worked under conditions that were hard to replicate. A large OEM could afford a forward-deployed expert, a bespoke integration effort, and the political sponsorship needed to protect a long pilot. Most organisations could not. The main barrier was the cost, risk, and organisational friction required just to find out whether the approach would pay off (rather than simply a lack of technical sophistication).
What changed
The shift over the last decade has come from the surrounding technical ecosystem rather than from a dramatic reinvention of the optimisation methods themselves.
GPU-backed cloud compute made it easier to run more experiments, train more models, and do so without buying dedicated internal HPC infrastructure. Python became the common language across large parts of the ML tooling stack, which made it easier to reuse statistical components from one problem domain to another. MATLAB and Simulink, which remain central in many engineering environments, became easier to drive programmatically through code generation, FMU export, and more open interfaces. Distributed messaging infrastructure such as Apache Kafka matured to the point where teams could route data from many upstream producers to many downstream consumers without writing a different integration for every pair of systems. Time-series databases and related tooling improved the handling of high-rate sensor data and reduced dependence on ad hoc combinations of spreadsheets, folders, and team-specific SQL stores.
At the same time, the calibration and testing problem itself became harder. Tighter emissions constraints, more complex control systems, and the rise of electrification increased the number of parameters and interactions that teams needed to manage. Battery behaviour, motor control, thermal systems, and hybrid powertrains added new optimisation burdens on top of existing internal combustion work. In many organisations, the workload grew faster than the number of people available to do it.
That combination created the commercial opening. Specialist teams had already proven that AI/ML techniques were useful and the pressure to automate had become stronger. And the surrounding software infrastructure was finally mature enough that startups could begin turning previously bespoke capabilities into products.
How industrial AI was productised
Productisation did not happen in one neat step. It happened in several related areas, each corresponding to one of the adoption barriers that had previously made these workflows expensive and fragile.
Automating test iterations
The first area was packaging the iterative method itself. In a research or consulting context, someone still has to decide which model family to use, how to represent uncertainty, and what rule should govern the selection of the next experiment. Those are meaningful technical choices, but they are not decisions most calibration engineers want to make before they can get any value. Productisation means pushing those choices down into the software. Instead of asking the engineer to select a kernel or compare several acquisition strategies, the product can run multiple models in parallel, combine their behaviour, surface disagreement or uncertainty, and then present a ranked list of candidate next tests. The user sees recommended operating points, not a menu of modelling assumptions. Monolith AI’s Next Test Recommender is a good example of this pattern. Across DoE, calibration, and related use cases, that sort of packaging has been associated with substantial reductions in campaign size and iteration time.
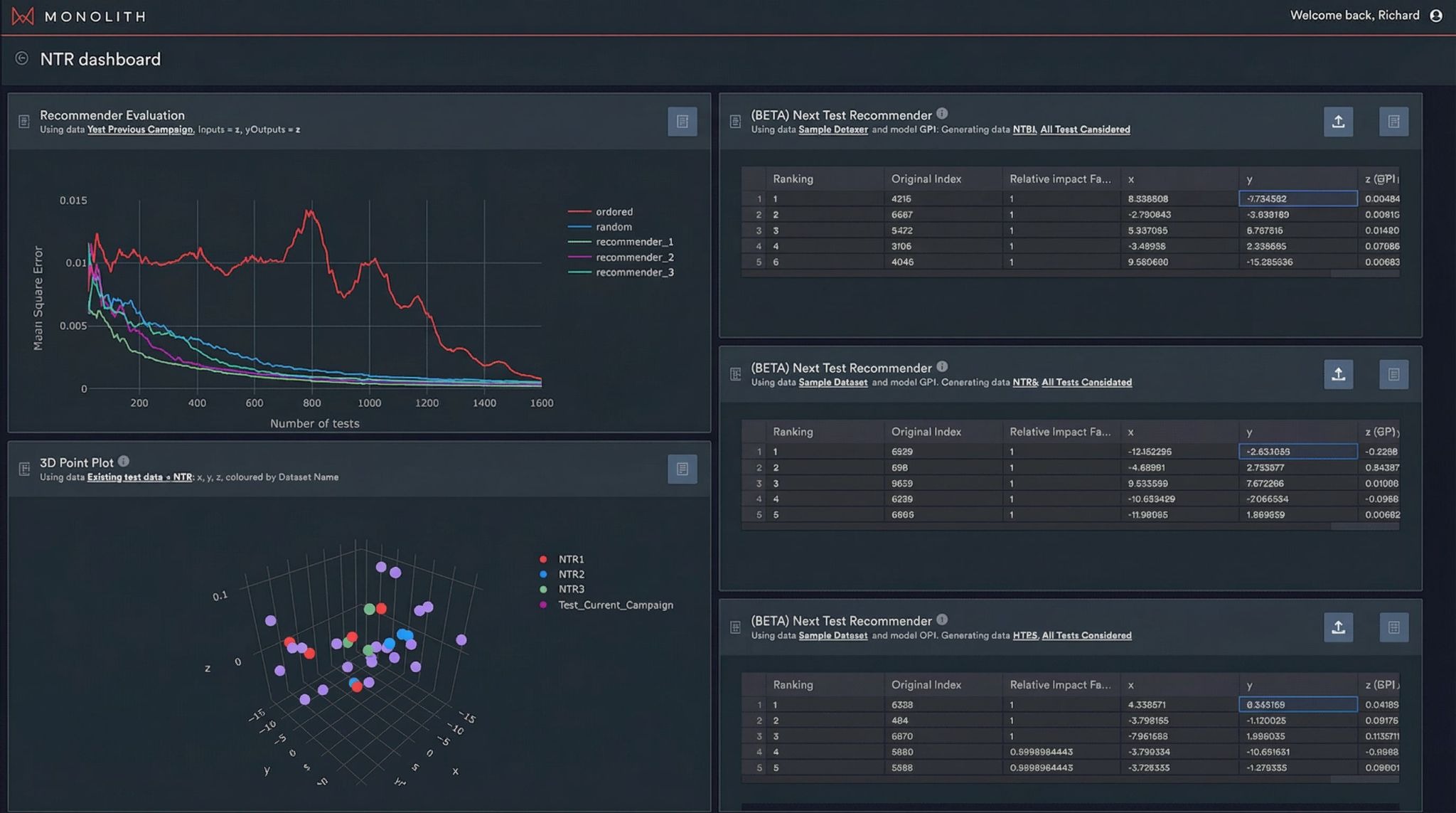
(from the whitepaper "3 Applications of AI in System Calibration Testing")
Integrating with the engineering toolchain
The second area was integration with the engineering toolchain. This is where many early projects spent most of their time. A functioning closed loop in calibration or test optimisation is not just a model. It is a sequence of systems passing information back and forth: a simulation or test bench runs a candidate point, results are ingested, the surrogate updates, the next proposed point is selected, and some execution environment needs to receive those parameters and run again. None of that is conceptually exotic, but building it reliably is still difficult. There are failures to handle, timestamps to align, missing data to reconcile, and domain-specific quirks to respect. Productisation here means building those connectors and orchestration paths once and reusing them, rather than rebuilding them from scratch for every new customer. Secondmind’s public work with Mazda is a useful example of this deeper level of integration, where the point is not just that a surrogate model exists, but that it has been tied into a working calibration workflow.
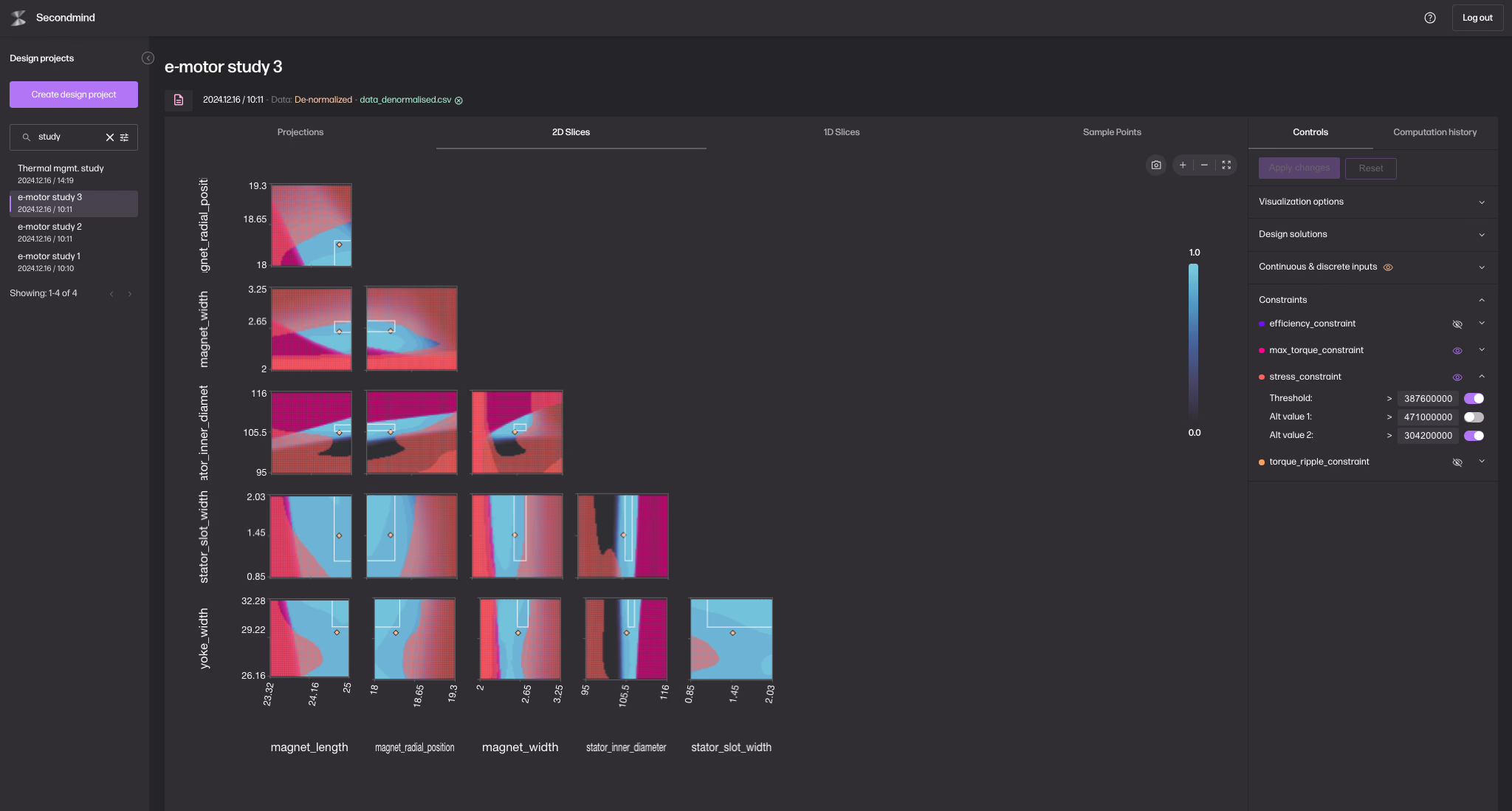
Building UIs that engineers can understand
The third area was the interface layer. Many industrial AI projects failed to travel beyond specialist teams because the software still expected the user to think like a data scientist. If the engineer has to understand modelling jargon before they can trust the recommendations, adoption will stall. Productised tools therefore tend to expose sensitivity analysis, comparisons, traceability, and explainability in engineering terms. This is important because an engineer is unlikely to follow a recommendation they cannot interrogate, especially when the recommendation suggests skipping tests they would otherwise consider routine.
Establishing a solid data backbone
The fourth area, and arguably the broadest, was the data foundation underneath everything else. Even a clean interface and a well-packaged test recommendation engine are not enough if the underlying data still lives in disconnected tools and incompatible formats. That includes not just live or recent test data, but historical campaign data as well. For many large manufacturers, decades of calibration, simulation, and test results are a real source of advantage, so any new system has to bring that history forward rather than strand it in legacy tools.
Earlier vendors often worked around this by integrating deeply with a relatively narrow toolchain inside each customer environment. That works well when the workflow is stable and the payoff from integration is clear. More recently, however, vendors have started building a broader class of products that provides shared data infrastructure for industrial R&D, rather than building a product around one specific use case (such as adaptive test recommendation or calibration).
For example, Quix provides teams with the underlying infrastructure and expertise to build their bespoke equivalents of similar SaaS products, including customizable dashboards and automated analysis pipelines. It comes with a message broker, data lake and Python-based orchestration layer needed to connect simulations, optimisation components, and physical systems into reusable workflows. It also gives teams a way to ingest and operationalize historical engineering data alongside live streams, so they can reuse past test, calibration, and simulation results instead of leaving them hidden away in legacy storage systems.
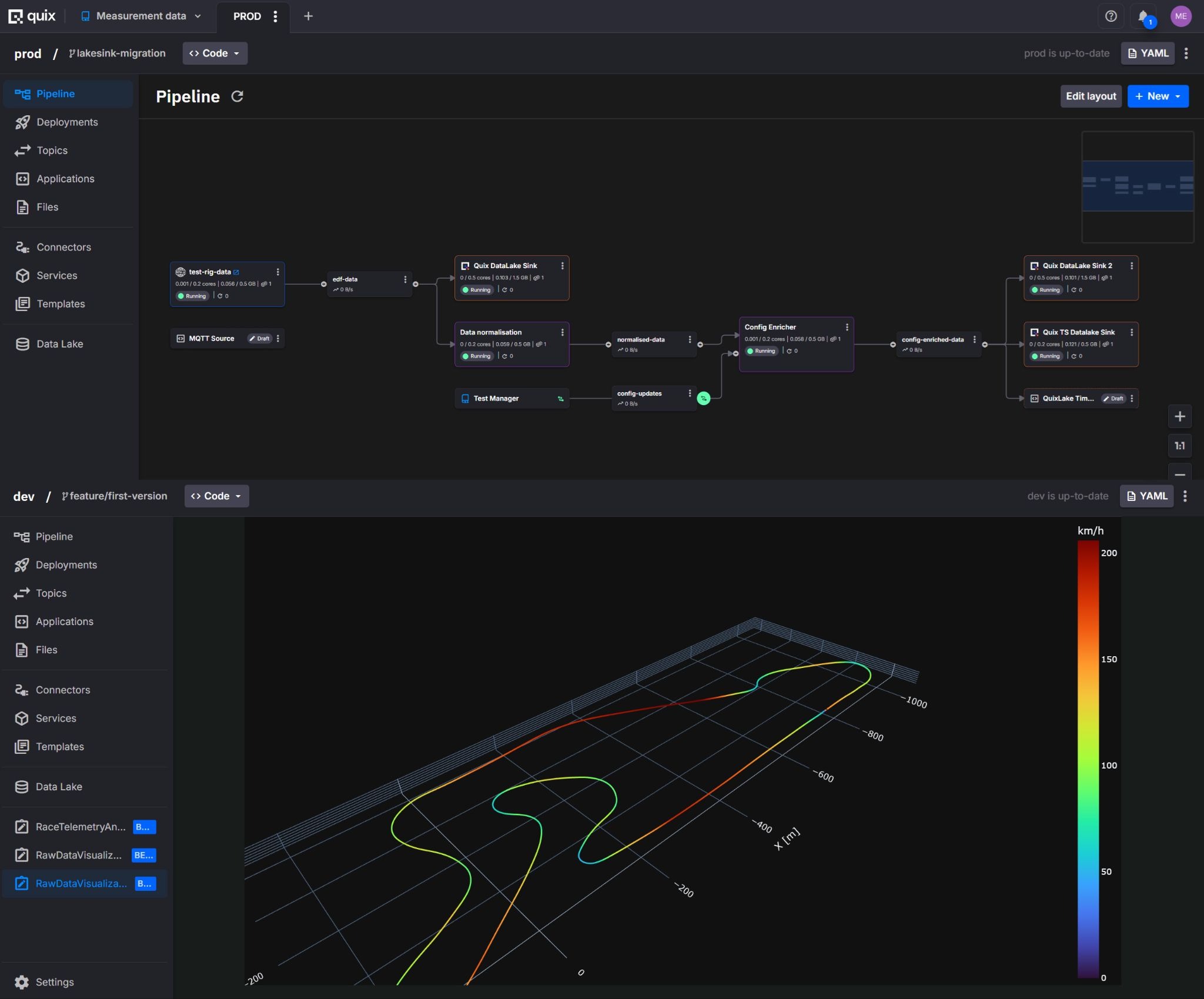
The products mentioned here are certainly not identical, and they do not solve the whole problem in the same way. The important point is that they all reduce pieces of the infrastructure burden that used to make industrial AI adoption disproportionately expensive.
What this means for R&D organisations
Taken together, these developments suggest that the economics of industrial AI adoption are changing. Techniques that have existed for years are becoming easier to try because the surrounding cost of implementation is falling.
That does not mean industrial R&D data has suddenly become tidy, standardised, or as frictionless as data in mainstream software environments. Industrial workflows are still full of incompatible vendors, local conventions, legacy formats, and domain-specific constraints. But it does mean that more of the underlying groundwork now exists in reusable form. The team evaluating an adaptive calibration loop or simulation optimization workflow no longer has to assume that it must first assemble a bespoke platform before any learning can begin.
That is a meaningful change in the build-versus-buy calculation. Previously, a company interested in applying these methods often had to fund a strategic internal effort just to get the software infrastructure in place: data ingestion, time alignment, storage, orchestration, model execution, and interfaces for engineers. Only then could it discover whether the optimisation logic created enough value to justify the effort. Today, some of those layers can increasingly be adopted off the shelf.
This is where an infrastructure-oriented product such as Quix fits. It is not a single, domain-specific optimisation tool. Instead, it provides the reusable workflow needed to move data between components, orchestrate independent services, and support an operational environment in which simulations, ML models, and test systems can all participate in the same closed loop. This is the infrastructural prerequisite for turning a technically plausible loop into one that is robust enough to run repeatedly across programmes, teams, and customers.
The practical effect is that engineering teams can spend more of their effort on problem-specific work: defining parameter spaces, deciding what to optimize, validating recommendations, and incorporating domain knowledge into the loop. The infrastructure does not disappear, but it becomes less likely to dominate the project.
At the same time, infrastructure does not eliminate the need for technical judgement. Someone still has to decide whether a proposed optimization target is meaningful, whether the data is trustworthy, whether a model recommendation is credible, and when the loop should be stopped. Productisation reduces the amount of custom engineering required to get started. It does not remove the need for engineers who understand both the system under test and the logic of the optimisation workflow.
Conclusion
The recent surge of attention around LLMs has made AI feel newly urgent across many industries, including engineering. But in industrial R&D, the more immediate gains are still coming from older methods: surrogate models, adaptive experiment design, simulation optimisation, and calibration workflows that learn from each iteration.
What held those methods back was not primarily a lack of model sophistication. It was the cost of making them usable inside real engineering organisations. Data was fragmented, toolchains were disconnected, expertise was scarce and most crucially, integration was bespoke. The reason adoption now looks more plausible is that those surrounding conditions are improving.
That is why infrastructure matters so much. When data can be ingested and aligned more easily, when execution environments can be connected without custom one-off integrations, when engineers can work through interfaces that speak their own language, and when orchestration layers can be reused across workflows, older AI methods stop looking like research projects and start looking like operational tools.
The main shift in industrial AI, then, is not that a new class of model has suddenly unlocked engineering value. It is that the infrastructure and productization needed to deploy established methods are finally catching up to the methods themselves.
Last updated:
Apr 27, 2026

Check out the repo
Our Python client library is open source, and brings DataFrames and the Python ecosystem to stream processing.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.


