.svg)
Configuration management pipeline reference architecture
How many times have your engineers said "we need to restart the whole system for a simple parameter change"? Configuration updates shouldn't bring testing to a standstill, yet most R&D teams accept this as an unavoidable reality. The cost in lost time and interrupted experiments adds up quickly.
Configuration changes in modern electro-mechanical systems can't wait for scheduled maintenance windows. Critical test sequences demand parameter tuning without interruption. Energy efficiency monitoring requires sensor calibration adjustments on the fly. You need real-time configuration management that doesn't interrupt operations.
About this reference architecture
The configuration management pipeline reference architecture provides a complete solution for managing configuration data across distributed R&D systems. This pre-configured pipeline handles everything from simple parameter updates to complex configuration files, enabling real-time changes without service interruptions.
Built on the Quix Framework, this reference architecture integrates seamlessly with your existing R&D infrastructure while providing the flexibility to scale from prototype testing to production deployment. The architecture supports multiple input sources, from custom web interfaces to file-based configuration systems, ensuring compatibility with your current workflows.
Configuration bottlenecks that slow R&D teams
R&D teams face mounting pressure to accelerate development cycles while maintaining rigorous testing standards. Traditional configuration management creates painful bottlenecks that slow innovation and frustrate engineers.
Consider a typical scenario: Your battery testing lab runs 24/7 thermal cycling experiments. When engineers need to adjust temperature thresholds or charging profiles, they must either wait for the next test cycle or restart the entire system - losing hours of valuable data. This same pattern repeats across disciplines, from aerospace teams adjusting flight parameters to automotive engineers tuning engine control maps.
The core issues plague every R&D organization:
Configuration drift across environments: Your simulation parameters don't match your test bench settings, which don't match your field deployment configurations. Engineers spend precious time hunting down the "correct" configuration, often reverting to email chains and shared network drives.
Manual update processes: Engineers manually edit configuration files, copy them to target systems, and restart services. This process takes 15-30 minutes per change and introduces human error at every step.
Version control chaos: Configuration history gets lost in file system folders or scattered across multiple repositories. When a test fails, engineers can't quickly identify which configuration version was running, making root cause analysis nearly impossible.
Large file handling: Complex systems generate configuration files that exceed 100MB - too large for traditional streaming data pipelines. These files get stored in random locations, creating data silos that prevent team collaboration.
Session-specific requirements: Different test runs require different parameter sets. Your robot arm might need high-precision settings for delicate component handling but faster, less precise settings for bulk material movement. Managing these variations manually becomes unmanageable as test complexity increases.
Regulatory compliance and traceability: Certification bodies demand complete documentation of which configuration versions were used in production systems. When aircraft software undergoes FAA certification or medical devices face FDA scrutiny, engineers must prove exactly which parameter sets were active during validation testing. A single missing configuration file or unclear version history can delay certification by months, costing millions in development time and market opportunities.
Real-time configuration management without service interruptions
The configuration management pipeline reference architecture addresses these challenges through a centralized, real-time configuration system that integrates with your existing tools and workflows.
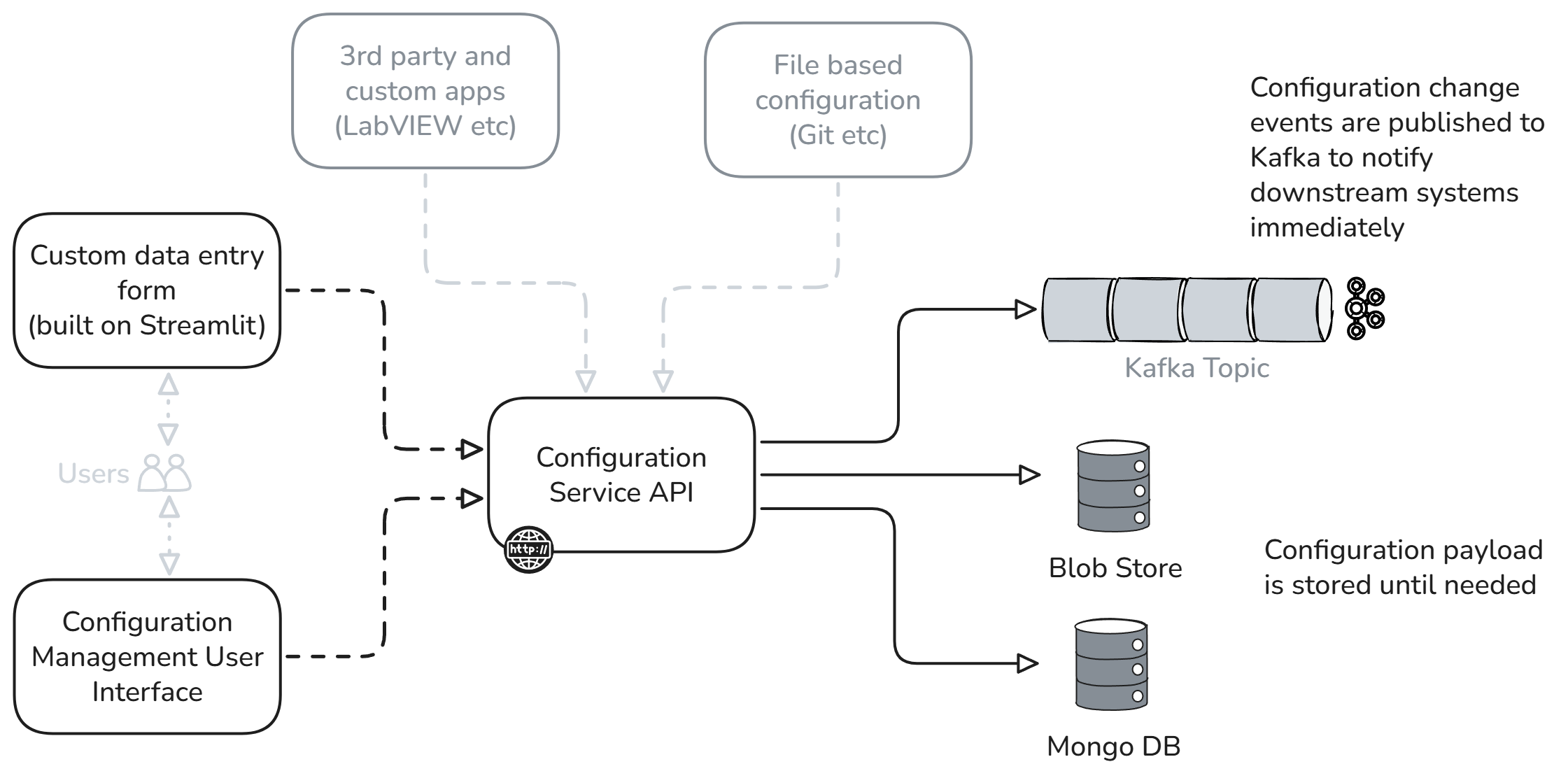
The architecture centers around a Configuration Service API that acts as the single source of truth for all configuration data. This API handles JSON configuration objects with automatic versioning, ensuring every change gets tracked and can be rolled back if needed.
Here's how the system works: When engineers need to update configurations, they use either the web-based Configuration Management User Interface or custom Streamlit forms tailored to their specific domain. The Configuration Service API validates these changes, assigns version numbers, and stores the data in both MongoDB for metadata and Blob Storage for large configuration files.
The magic happens next. Configuration changes get published to a Kafka topic, immediately notifying all downstream systems. Running simulations, test equipment, and analysis tools receive these updates in real-time without requiring restarts or manual intervention.
Third-party applications integrate through the API, whether they're LabVIEW measurement systems, MATLAB simulation environments, or custom analysis tools. File-based configurations from Git repositories or network shares get automatically ingested and synchronized across your infrastructure.
The system handles both lightweight parameter updates (sensor thresholds, algorithm coefficients) and heavyweight configuration files (neural network models, simulation scenarios, test procedures). Large files get stored efficiently in blob storage while metadata enables fast searching and filtering.
Key features of this reference architecture
Real-time configuration updates: Changes propagate to running systems within seconds through Kafka messaging. Battery testing rigs receive updated charging parameters while tests continue running, eliminating the need for restart cycles that waste hours of data collection.
Automatic versioning and auditing: Every configuration change gets tracked with timestamps, version numbers, and metadata. When autonomous vehicle perception systems behave unexpectedly, engineers can instantly identify which configuration version was active and compare it with previous working versions.
Hybrid storage architecture: Small configurations get stored in MongoDB for fast querying, while large files (simulation models, test procedures) get stored in blob storage. This approach handles everything from simple parameter files to 500MB neural network models without performance degradation.
Session-specific configuration management: Different test runs can use different configuration sets without conflicts. Rocket engine test stands can run multiple experiments simultaneously, each with its own parameter set, while maintaining clear separation and traceability.
Streamlit integration for domain-specific interfaces: Create custom configuration forms tailored to your engineering domains. Battery engineers get forms optimized for electrochemical parameters, while thermal engineers get interfaces designed for heat transfer coefficients and material properties.
Comprehensive validation and error handling: The system validates JSON format compliance and enforces business rules specific to your domain. Invalid configurations get rejected before they can impact running systems, preventing costly test failures.
Caching and performance optimization: Frequently accessed configurations get cached to reduce API load and improve response times. High-frequency control systems can access configuration data with sub-millisecond latency.
Code sample
Here's how to implement configuration updates in your Python applications:
import json
from quix_streams import Application
from config_service_client import ConfigurationClient
# Initialize the configuration client
config_client = ConfigurationClient(api_url="https://config-api.yourcompany.com")
# Create a Quix application to listen for configuration changes
app = Application(broker_address="kafka.yourcompany.com:9092")
# Subscribe to configuration change notifications
config_topic = app.topic("configuration-updates")
def handle_config_change(message):
"""Process configuration change notifications"""
config_data = json.loads(message.value)
# Extract configuration metadata
config_id = config_data["id"]
version = config_data["version"]
target_key = config_data["target_key"]
# Fetch the full configuration from the API
full_config = config_client.get_configuration(config_id, version)
# Apply configuration to your system
apply_configuration(target_key, full_config)
print(f"Applied configuration {config_id} v{version} to {target_key}")
def apply_configuration(target_key, config_data):
"""Apply configuration changes to your system"""
if target_key == "battery_test_parameters":
# Update battery testing parameters
update_battery_thresholds(config_data)
elif target_key == "vision_system_config":
# Update computer vision parameters
update_vision_parameters(config_data)
# Add more target handlers as needed
# Start listening for configuration changes
with app.get_consumer() as consumer:
consumer.subscribe([config_topic])
for message in consumer:
handle_config_change(message)This code demonstrates how your applications can receive and apply configuration changes in real-time, ensuring your systems stay synchronized with the latest parameter sets.
Accelerating R&D cycles with centralized configuration control
The configuration management pipeline reference architecture transforms how R&D teams handle configuration data, eliminating the bottlenecks that slow development cycles and frustrate engineers. By providing real-time updates, automatic versioning, and seamless integration with existing tools, this architecture enables your teams to focus on innovation rather than infrastructure management.
The system's ability to handle both lightweight parameter updates and complex configuration files makes it suitable for any R&D environment, from small research labs to large-scale industrial testing facilities. The combination of web interfaces, API integration, and real-time messaging ensures that configuration changes propagate instantly across your entire infrastructure.
Engineers can now adjust drone flight parameters during test flights, update battery charging algorithms during thermal cycling, and modify HVAC control strategies during efficiency testing - all without interrupting operations or losing valuable data.
Ready to eliminate configuration management bottlenecks in your R&D operations? Explore the configuration management pipeline reference architecture and discover how centralized configuration management can accelerate your development cycles while maintaining the rigorous standards your engineering teams demand.
Using this template
This blueprint can be useful for the following use cases:
• R&D
• Test Chamber
• Test Run
• Simulation
• Digital Twin
Main project components
Technologies used

