.svg)
Ecosystem
Jul 9, 2024
How to fix common issues when using Spark Structured Streaming with PySpark and Kafka
A look at five common issues you might face when working with Structured Streaming, PySpark, and Kafka, along with practical steps to help you overcome them.


Introduction
Spark Structured Streaming is a distributed stream processing engine built on the Spark SQL engine. It offers high-level Dataset/DataFrame APIs that you can use to process data streams in real time (or in micro batches, depending on your preference). Structured Streaming supports a rich set of capabilities, including stream joins, windowed aggregations, stateful operations, checkpointing, and exactly-once processing.
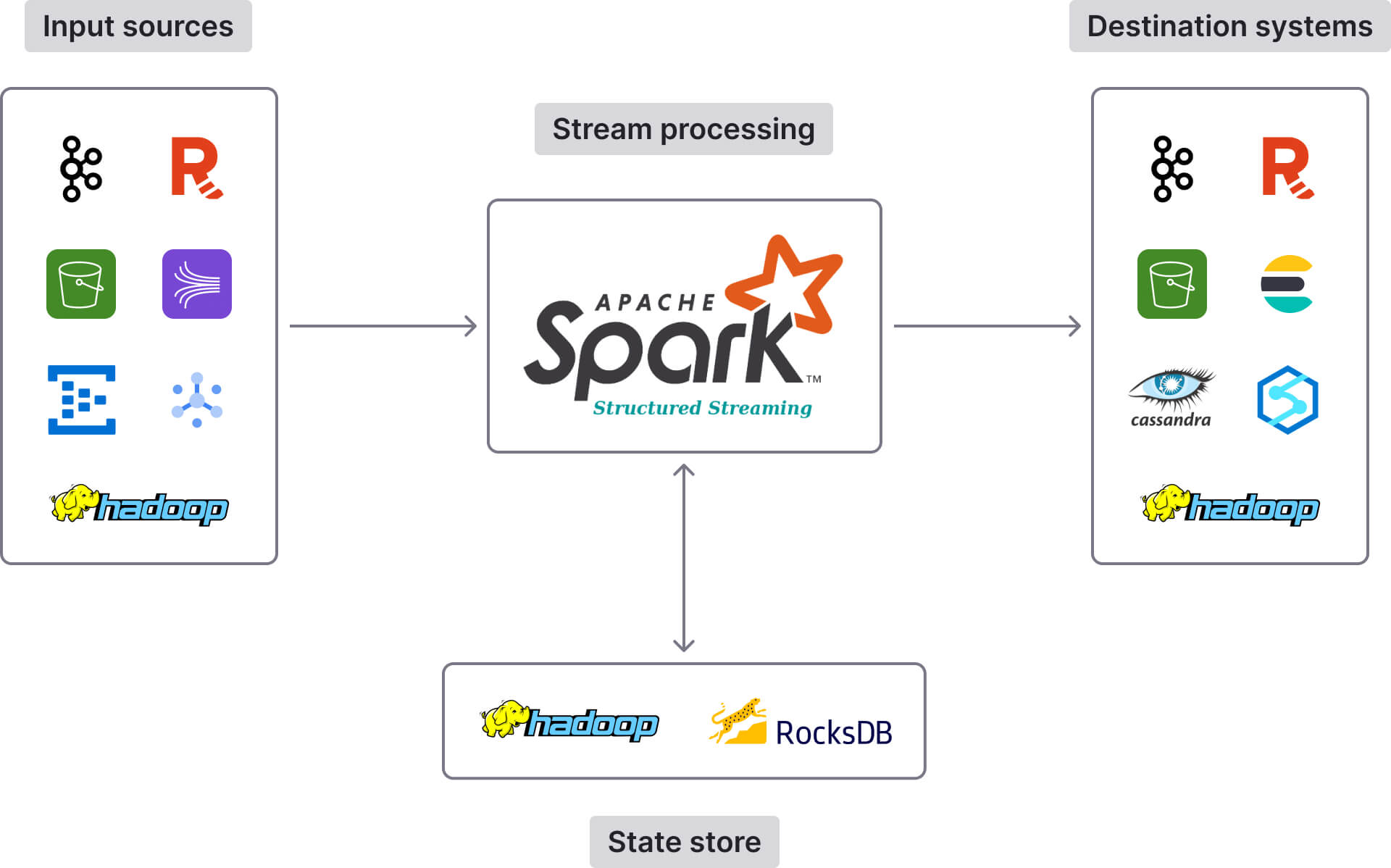
PySpark brings the power of scalable and fault-tolerant stream processing (via Spark Structured Streaming) to the Python ecosystem. This is a significant advantage, as most stream processors primarily target Java and Scala developers.
While it’s great that Spark Structured Streaming and PySpark make it possible to implement Python stream processing logic, doing so is not always a walk in the park. Structured Streaming is a sophisticated server-side engine, and it takes a long time to master its features and capabilities.
Meanwhile, PySpark is a wrapper (not a native Python API), which can introduce some challenges with the application code. For example, PySpark errors often show both Java stack trace errors and references to the Python code, making it difficult to debug PySpark applications.
Running and deploying stream processing applications built with Structured Streaming and PySpark can be tricky due to intricate dependency management and configuration complexities.
In this article, I will present five common issues you might encounter when using PySpark and Spark Structured Streaming to build stream processing pipelines. Specifically, pipelines where Kafka is the data source. Kafka is commonly paired with stream processing engines to build scalable, high-performance data pipelines. In fact, it’s probably the most popular source and sink destination for any stream processing component, be it Spark or an alternative solution.
All issues we’ll review are raised on Stack Overflow, each with thousands of views. The first three issues relate to application code, while the last two concern job deployment.
Issue No. 1 – Application does not act on the data, such as printing to the console
In the “Read data from Kafka and print to console with Spark Structured Streaming in Python” discussion on Stack Overflow, a user mentioned they configured a Spark session to subscribe to a Kafka topic and read from it. However, despite running the code without errors and confirming the schema, no data appeared in the output.
Clearly, this issue hits home for many developers – the Stack Overflow post has over 24,000 views.
Anyway, here’s the code that led to the issue:
spark = SparkSession \
.builder \
.appName("APP") \
.getOrCreate()
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "sparktest") \
.option("startingOffsets", "earliest") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
df.printSchema()
Cause and solution
The underlying cause is a misunderstanding of how Spark Structured Streaming handles data: Spark's lazy evaluation nature requires an action to trigger data processing. The user's initial code only defines the schema and data stream, but doesn't include an action that outputs the data.
The solution to this problem is to add a writeStream operation to the DataFrame that continuously outputs the data to the console:
spark = SparkSession \
.builder \
.appName("APP") \
.getOrCreate()
df = spark\
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "sparktest") \
.option("startingOffsets", "earliest") \
.load()
query = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") \
.writeStream \
.format("console") \
.option("checkpointLocation", "path/to/HDFS/dir") \
.start()
query.awaitTermination()
Note that if the streaming query is set up but not started with .start() or if .awaitTermination() is not called, the application may exit before any output is produced.
Issue No. 2 – Set() are gone. Some data may have been missed
In the “PySpark and Kafka - Set are gone. Some data may have been missed” discussion on Stack Overflow, a user mentioned they received the following error when trying to write a streaming DataFrame to a Kafka topic:
Set() are gone. Some data may have been missed.
Here’s the full, more verbose version:
java.lang.IllegalStateException: Set() are gone. Some data may have been missed.. Some data may have been lost because they are not available in Kafka any more; either the data was aged out by Kafka or the topic may have been deleted before all the data in the topic was processed. If you don't want your streaming query to fail on such cases, set the source option "failOnDataLoss" to "false".
Cause and solutions
The error typically occurs because Kafka has removed some messages/offsets from the source topic due to its cleanup policies, like retention time. This leads to a situation where the Spark Structured Streaming query tries to fetch data from an offset that is no longer available (it’s maintained in the Spark checkpoint files but deleted from Kafka).
Below, I present solutions to this problem.
Delete Spark checkpoint files
First, you have to stop the streaming query. Then, delete the directory where the Spark checkpoint files are stored. Finally, restart the query.
By deleting the checkpoint files, you essentially force the Spark Structured Streaming job to reset and start from the earliest available Kafka offset (with a new set of checkpoint files being created).
Set failOnDataLoss to false
As indicated by the text of the error itself, another thing you can do is set the failOnDataLoss option to false. You can do this in the readStream operation of the job, like in this example:
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "your-kafka-topic") \
.option("failOnDataLoss", "false") \
.load()
df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
This prevents the query from failing and allows it to continue running. However, as discussed in the “How to recover from a Kafka topic reset in Spark Structured Streaming” blog post, setting failOnDataLoss to false doesn’t solve the underlying issue of potential data loss. If you’re reading from a Kafka topic that has been deleted and recreated (with new offsets), you might get a warning that looks something like this:
WARN KafkaMicroBatchReader: Partition test-topic-0's offset was changed from 500 to 300, some data may have been missed.
Some data may have been lost because they are not available in Kafka any more; either the data was aged out by Kafka or the topic may have been deleted before all the data in the topic was processed. If you want your streaming query to fail on such cases, set the source option "failOnDataLoss" to "true".
Best practices to prevent data loss
If data integrity is imperative to your use case, and you don’t want to lose any data, here are some best practices to have in mind:
- Avoid routinely deleting and recreating Kafka topics that lead to changes in offsets.
- Ensure that Kafka's retention policy is set to retain messages long enough for your Spark Structured Streaming job to read and process them. This minimizes the risk of data loss due to message expiration.
- Restart the Spark query before any new data has been published to the topic that you have reset (so they both start from an offset of 0).
- In your application code, set the Spark Structured Streaming
startingOffsetsconfiguration toearliest, so that the data processing job begins reading data from the earliest available message in each partition of the Kafka topic. Here’s a snippet demonstrating how you can do this:
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", kafka_bootstrap_servers) \
.option("subscribe", kafka_topic) \
.option("startingOffsets", "earliest") \
.load()
Issue No. 3 – Parsing JSON data from Kafka
JSON is one of the most popular data formats used with Kafka. So, if you’re building PySpark Structured Streaming applications consuming from Kafka, there’s a good chance you will have to parse JSON Kafka data into a structured DataFrame (so the Spark engine can process it).
Yet, some people have found this to be problematic, as illustrated by the following Stack Overflow posts:
- Can't transform Kafka JSON data in Spark Structured Streaming — a user mentions they’ve struggled to parse JSON messages from Kafka into a specific schema for further processing (the parsed data was outputting as null).
- Create a data frame from JSON coming from Kafka using Spark Structured Streaming in Python — a user complains that, although they were able to fetch JSON from Kafka and parse it into a DataFrame, the DataFrame didn’t display the properties as intended.
Problems and solutions
To help you bypass and troubleshoot such annoying parsing issues, here are some recommendations you can follow:
Clean up JSON data
JSON data fetched from Kafka might have unwanted characters, such as escape sequences or extraneous quotes that might prevent correct parsing. Fortunately, you can get rid of them by using the regexp_replace function. Here’s an example showing how:
# Define the schema that matches your JSON data
schema = StructType([
StructField("property1", StringType(), True),
StructField("property2", StringType(), True)
])
# Read from Kafka
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "localhost:9092") \
.option("subscribe", "my_kafka_topic") \
.load() \
.select(col("value").cast("string"))
# Clean up the JSON strings
df_clean = df.withColumn("value", regexp_replace(col("value"), "\\\\", "")) \
.withColumn("value", regexp_replace(col("value"), "^\"|\"$", ""))
To clarify, regexp_replace(col("value"), "\\\\", "") removes backslashes, which are used as escape characters in JSON strings, while regexp_replace(col("value"), "^\"|\"$", "") removes leading and trailing double quotes from JSON strings.
Make sure the schema is properly defined
You have to make sure that the schema defined in Spark matches the JSON structure exactly. Any discrepancies can lead to null values or incorrect data parsing. The StructType and StructField classes help you define the schema. For instance, if your JSON messages contain two fields, property1 and property2, both of which are strings, you would define your schema as follows:
schema = StructType([
StructField("property1", StringType(), True),
StructField("property2", StringType(), True),
])
Flatten nested JSON when appropriate
Sometimes it might be beneficial to transform nested JSON structures into flat columns. This process makes the data more accessible and usable, allowing for straightforward SQL queries and efficient data manipulation. For example, after parsing JSON, you might use:
.select(col("parsed_value.propertyget1"), col("parsed_value.property2"))
This code snippet selects specific properties from the parsed JSON, making them directly accessible as individual DataFrame columns.
Alternatively, to flatten and access all elements of a nested JSON, you can use:
.select(col("parsed_value.*"))
The wildcard (*) selects all fields within the parsed_value JSON object and flattens them into individual DataFrame columns. This means every key in the nested JSON becomes a separate column in the DataFrame.
While I’ve mentioned the benefits of flattening nested JSON, there are some caveats, too:
- If the JSON is deeply nested or contains many keys, flattening it will create a large number of columns, which could potentially make the DataFrame cumbersome to manage and slower to process.
- If different nested JSON objects contain keys with the same name, using a wildcard can lead to column naming conflicts, resulting in errors or the need to rename columns.
Issue No. 4 – AnalysisException: Failed to find data source: kafka
Submitting a job for an application that connects to Kafka may result in the following error:
AnalysisException: Failed to find data source: kafka
Or the more verbose variant:
pyspark.sql.utils.AnalysisException:Failed to find data source: kafka. Please deploy the application as per the deployment section of "Structured Streaming + Kafka Integration Guide".;
This seems to be one of the most common issues when using Spark Structured Streaming and PySpark. It has been raised in multiple Stack Overflow posts, such as:
Causes and solutions
There are several different reasons that might trigger the error, each with its own solution.
Wrong sequence of arguments
The error can be caused due to an incorrect sequence of arguments when launching the application. For instance, the following spark-submit example would trigger the error:
./bin/spark-submit MyPythonScript.py --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1 [additional arguments]
That’s because the --packages flag must precede the script name to ensure dependencies are loaded beforehand. Here’s the correct way to do it:
./bin/spark-submit --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1 [additional arguments] MyPythonScript.py
Wrong Kafka source package
The AnalysisException: Failed to find data source: kafka error might also be triggered if you don’t specify the correct Kafka source package for Structured Streaming (spark-sql-kafka-0-10_2.12 at the time of writing) or use an incorrect version of it that doesn't match the installed Spark version.
For example, if you have Spark version 3.5.1 installed, the package version should be spark-sql-kafka-0-10_2.12:3.5.1. On the other hand, if you are using Spark 3.4.0, the package version should be spark-sql-kafka-0-10_2.12:3.4.0.
Not all nodes have access to the required JARs
You might also encounter this error if you’re using Spark in a distributed cluster and not all nodes have access to the required JARs (e.g., application JARs, dependency JARs, the Kafka source package for Structured Streaming JAR). There are several different ways to counter this and ensure JARs are available to all the executor nodes in the cluster.
For example, you could use the --jars option with spark-submit, like in this example:
./bin/spark-submit \
--jars path/to/your/jarfile1.jar,path/to/your/jarfile2.jar \
/path/to/MyPythonScript.py
Check out the Submitting Applications page of the Spark documentation to discover more about spark-submit.
You can also specify JARs in the Spark configuration file (spark-defaults.conf), using the spark.jars property:
# In spark-defaults.conf
spark.jars path/to/jar1.jar,path/to/jar2.jar
To learn more about spark-defaults.conf, refer to the Spark Configuration documentation.
With the two approaches presented above, Spark internally handles the distribution of these JAR files to all the executor nodes. This means Spark will copy the JAR files from the location specified on the machine where you submit the job to each node in the cluster.
There’s also a third option: you can place the JAR files in a shared filesystem (like HDFS, S3, NFS) and give cluster nodes access to it. You still need to reference these JARs in your Spark job configuration (using --jars or spark.jars, as demonstrated in the two snippets above), but instead of Spark copying the files to each node, the nodes directly access the JAR files from the shared location.
Typos in the values of Kafka parameters
Finally, the AnalysisException: Failed to find data source: kafka error might pop up if you have typos in the values you set for Kafka-specific parameters (such as kafka.bootstrap.servers or topic), so make sure you’ve specified them correctly. For reference, you can configure Kafka parameters directly in the application code, using the option method of the DataFrame read/write operations for Kafka. Here’s an example:
df = spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.option("subscribe", "topic1") \
.option("includeHeaders", "true") \
.load()
Alternatively, you can configure Kafka-specific parameters using any of the following options:
- In the application code via the
SparkConfobject. - In the
spark-defaults.confconfiguration file. - In the
spark-submitcommand, using--conf.
Issue No.5 – Failed to construct kafka consumer, Failed to load SSL keystore
You can deploy Spark jobs in various environments, including your local machine, on-prem clusters, Kubernetes, and managed cloud platforms. Each environment presents unique challenges for setting up, executing, and managing Spark jobs.
In the “GCP Dataproc - Failed to construct kafka consumer, Failed to load SSL keystore dataproc.jks of type JKS” discussion on Stack Overflow, a user mentioned they hit a stumbling block when trying to deploy a PySpark Structured Streaming job on Google Cloud Dataproc. Specifically, they were presented with a couple of errors:
# The rest of the code is omitted for brevity
# Error in constructing Kafka consumer
org.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most recent failure: Lost task 0.3 in stage 0.0 (TID 3) (executor_hostname executor_id): org.apache.kafka.common.KafkaException: Failed to construct kafka consumer
# Error loading SSL keystore needed for Kafka SSL configuration
org.apache.kafka.common.KafkaError: Failed to load SSL keystore /path/to/your/keystore.jks of type JKS
Cause and solutions
For more context, the PySpark job was supposed to interact with a Kafka data source using SSL. The SSL truststore and keystore files were stored on Google Cloud Storage so they could be used by the job (or at least that was the intention). However, when the job tried to start reading data from Kafka using the SSL configuration files, the two errors occurred.
The underlying issue was that the truststore and keystore files were downloaded to the directory where the Spark driver was running, but they were not automatically accessible to Spark executor processes running on other nodes in the cluster (you have to configure this yourself).
If you ever come across such a situation, there are a couple of things you have to do.
Ensure that every executor node has a local copy of the necessary SSL files
You can do this by using the --files option with the gcloud command, like in the following example:
# Submit a PySpark job to a Dataproc cluster with SSL configuration files distributed
gcloud dataproc jobs submit pyspark /path/to/your/spark-script.py \
--cluster=your-dataproc-cluster \ # Specify the name of your Dataproc cluster
--region=your-region \ # Specify the region of your Dataproc cluster
--files=/local/path/to/truststore.jks,/local/path/to/keystore.jks \ # Comma-separated list of local SSL files to distribute
--properties=spark.jars.packages=org.apache.spark:spark-sql-kafka-0-10_2.12:3.5.1, \
spark.executor.extraJavaOptions="-Djavax.net.ssl.trustStore=/path/on/executor/truststore.jks \
-Djavax.net.ssl.trustStorePassword=truststore-password \
-Djavax.net.ssl.keyStore=/path/on/executor/keystore.jks \
-Djavax.net.ssl.keyStorePassword=keystore-password"
When you submit the job, the system uploads the specified files to the driver node and then copies them to each executor node.
Configure your PySpark application to reference the distributed SSL files correctly
Your need to ensure your PySpark application correctly references the distributed files, i.e., paths are set relative to the executor's environment rather than the driver's filesystem.
For instance, let’s assume you initially configured your SSL truststore and keystore files with absolute paths specific to your driver's filesystem, like in this snippet:
ssl_truststore_location = "/path/on/driver/truststore.jks"
ssl_keystore_location = "/path/on/driver/keystore.jks"
You would need to change them to relative paths accessible to each executor:
ssl_truststore_location = "truststore.jks"
ssl_keystore_location = "keystore.jks"
Here’s the complete configuration:
# Define the locations of the SSL truststore and keystore files
ssl_truststore_location = "truststore.jks"
ssl_keystore_location = "keystore.jks"
# Kafka and SSL configuration settings
kafkaBrokers = "kafka-broker1:9093,kafka-broker2:9093" # Adjust the brokers' list as needed
topic = "your-kafka-topic"
consumerGroupId = "your-consumer-group-id"
ssl_truststore_password = "your-truststore-password"
ssl_keystore_password = "your-keystore-password"
# Read data from Kafka using structured streaming
df_stream = spark.readStream.format('kafka') \
.option("kafka.bootstrap.servers", kafkaBrokers) \
.option("kafka.security.protocol", "SSL") \
.option("kafka.ssl.truststore.location", ssl_truststore_location) \
.option("kafka.ssl.truststore.password", ssl_truststore_password) \
.option("kafka.ssl.keystore.location", ssl_keystore_location) \
.option("kafka.ssl.keystore.password", ssl_keystore_password) \
.option("subscribe", topic) \
.option("kafka.group.id", consumerGroupId) \
.option("startingOffsets", "earliest") \
.option("failOnDataLoss", "false") \
.option("maxOffsetsPerTrigger", 10) \
.load()
Once you’ve implemented these two configurations, the PySpark Structured Streaming job should be able to run without throwing any Failed to construct kafka consumer and Failed to load SSL keystore… errors.
Concluding thoughts on the challenges of using PySpark with Spark Structured Streaming and Kafka
While powerful, Spark Structured Streaming's complexity can lead to a steep learning curve and significant operational overhead. As a server-side engine, it requires you to submit your applications to run on a cluster, separate from the rest of your application logic, and manage various dependencies.
PySpark, albeit one of the few Python APIs around for building stream processing applications, also has its limitations. Being a wrapper around the JVM-based Spark, it requires JAR files and other Java dependencies to connect to Kafka.
Debugging applications built with PySpark and Structured Streaming is challenging because data serialization and deserialization between Python and the JVM can lead to obscure error messages and performance overhead. Furthermore, errors in the distributed Spark environment are often hard to trace back to the original Python code, making it difficult to pinpoint and fix issues.
Simplify Python stream processing with Quix Streams
If you’d like to avoid the complexities of using PySpark and Spark Structured Streaming to build Python stream processing pipelines, you could look into an alternative solution such as Quix Streams.
Quix Streams is an open-source, cloud-native library for processing data in Kafka using pure Python. It’s designed to give you the power of a distributed system in a lightweight library by combining the low-level scalability and resiliency features of Kafka with an easy-to-use Python interface. Here are some of its key advantages compared to PySpark and Structured Streaming:
- Pure Python, with an intuitive, straightforward Streaming DataFrame API.
- No JVM, wrappers, or DSL, greatly simplifying the development and debugging experience.
- Natively supports Kafka, with no extra dependencies (i.e., there’s no JAR).
- Client-side library that you can embed in any program written in Python.
- You can deploy Quix Streams applications as Docker containers in Kubernetes or within whatever deployment platform you want. Since Quix Streams uses Docker, it’s much easier to add system dependencies or libraries to support your applications.
- Seamless integration with Quix Cloud, a fully managed enterprise-grade platform for deploying Quix Streams applications. Quix Cloud comes with a visual DAG editor, CI/CD, monitoring, and managed Kafka.
To learn more, check out the Quix Streams documentation and GitHub repo.
Last updated:
Jul 16, 2024

Check out the repo
Our Python client library is open source, and brings DataFrames and the Python ecosystem to stream processing.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.



