.svg)
Data ingestion and configuration management
Why is configuration metadata important
Configuration metadata is critical to creating high quality datasets because it allows you to create a reproducible, single source of truth, version controlled, log of all the configuration changes that occur throughout the experiments and tests that are run during the development lifecycle of a product.
A key technical challenge in managing configuration metadata is combining it with your test datasets, especially when there are many teams collaborating on the test plan, the tests are running constantly and the configuration of each test is changing iteratively.
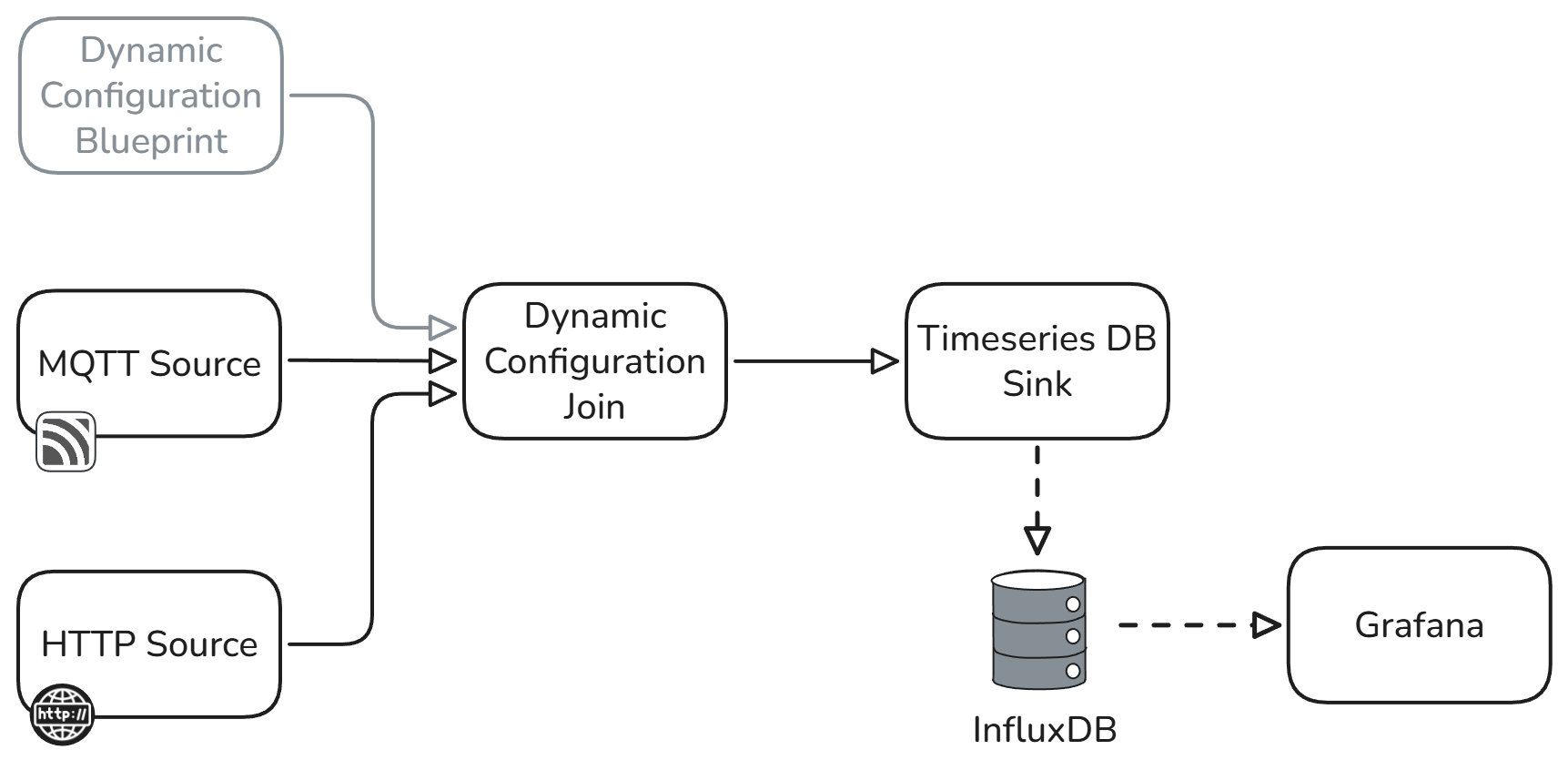
This reference architecture helps Python Software Engineers to build a system that joins configuration changes, from multiple teams and subsystems, with live data in real-time, without requiring service restarts. This pluggable blueprint allows a large number of different configuration payloads to be ingested from any source and merged with the test data, whilst maintaining unique IDs and timestamps to create a versioned catalogue of all test datasets.
The configuration management problem
Testing complex systems requires a vast amount of configuration meta data and can output large quantities of time-series data. Failure to accurately record configuration data against the corresponding test data can lead to reduced efficiency in determining successful outcomes because:
• Fragmented Data caused by teams maintaining individual configurations for their own subsystems of complex projects and having manual handoff of these configurations.
• Collaboration Challenges caused distributed teams local subsystem configuration and manual configuration handoff between teams.
• Compliance and Traceability Gaps causes difficulty in maintaining regulatory audit trails, challenges in tracing test results back to specific configurations and inadequate documentation for compliance with industry standards.
• Operational Inefficiency caused by significant time spent on manual configuration changes and tracing errors due to manual entry mistakes, high risk of human error, delayed root cause analysis and test validation.
• Scalability Issues caused by complex manual processes means consistency and speed are unmaintainable.
• Integration Challenges caused by incompatible tools and systems. Requiring fragile, bespoke solutions and workarounds.
A solution to configuration management issues
This configuration management blueprint specifically addresses the problem of merging configuration data with live test data to create a high quality test results database that is indexed by configuration. It provides engineers with analytics ready data and allows them to quickly identify issues, compare test runs and audit test results using configuration metadata.
This reference architecture is built on top of the Quix framework which provides a customizable, scalable, maintainable and secure base to build upon. Read more about the Quix architecture here.
Key features of this reference architecture
• Time-Series Test Data: Live time-series test data is ingested directly from test equipment or simulations via HTTP and MQTT sources. Additional sources can be added via the App gallery such as OPC-UA, CSV or database.
• Configuration Ingestion: The Configuration Ingestion blueprint enables dynamic configuration metadata ingestion, both before and during a test run, from any source in any size, format and velocity, without forcing service restarts. For example configuration data stored in GitHub or BitBucket repositories, LabView or any other tooling capable of HTTP communication.
• Data & Configuration Join: Live time-series test data is joined with all configuration metadata with unique IDs for the test and configurations, even while models are running, providing powerful indexing for later retrieval and analysis.
• Time Series DB Sink: Time-series test data is tagged with configuration meta data creating a high-quality and indexed data catalogue.
• Visualisation: Grafana, a simple and common tool for data visualizations is provided to allow engineers to easily search, filter and compare data sets based on time-series data or configuration attributes.
• Scalability: Built on the Quix framework, this reference architecture is already scalable and can handle large volumes of test data and dynamically changing configurations from hundreds of diverse sources.
• Resilience: The Quix framework affords the reference architecture with built-in resilience enabling it to handle outages and failures. When combined with the Application Monitoring blueprint, the reference architecture can provide fine grained visibility into the health of the system.
• Standardisation: The Quix framework helps enforce industry standard version control of configuration changes. You will always know the who, when and why for every configuration change.
Code example
The “Dynamic Configuration Join” service in the reference architecture requires customization to meet the specific requirements being implemented. Comprehensive code samples and reference applications have been provided to assist Python Software Engineers to achieve the required results.
In this code example, measurement data is joined with metadata using an ‘inner’ join with a grace period of 14 days, meaning that late arriving records have 14 days to be included in the join.
from datetime import timedelta
from quixstreams import Application
app = Application(...)
sdf_measurements = app.dataframe(app.topic("measurements"))
sdf_metadata = app.dataframe(app.topic("metadata"))
# Join records from the topic "measurements"
# with the latest effective records from the topic "metadata".
# using the "inner" join strategy and keeping the "metadata"
# records stored for 14 days in event time.
sdf_joined = sdf_measurements.join_asof(
right=sdf_metadata,
how="inner",
on_merge="keep-left",
grace_ms=timedelta(days=14),
)
if __name__ == '__main__':
app.run()
Several options are available to the Engineers such as how long to wait for late arriving data, the grace period, and how to perform the join, e.g. ‘inner’. For full details and more examples, visit the Quix Docs.
Focus your effort
Dedicated R&D teams can now focus on their core goals without having to worry about sharing configurations or updating other teams manually and software engineers can focus on building valuable features on top of the Quix blueprints without having to worry about the complexities of security, scalability, resilience and maintainability.
Using this template
This blueprint can be useful for the following use cases:
• R&D
• Test Chamber
• Test Run
• Simulation
• Digital Twin
Main project components
Technologies used

