A practical introduction to stream reprocessing in Python
Learn how to reprocess a stream of data with the Quix Streams Python library and Apache Kafka. You'll ingest some GPS telemetry data into a topic and replay the stream to try out different distance calculation methods.




One big advantage of streaming architectures is the ability to “replay” a stream and reprocess the data in different ways. This can seem like an alien concept if you’re used to architectures where data is processed in batches. To better understand it, I’ve created a simple to tutorial to show how it works in practice. You’ll ingest some sample telemetry data recorded from test journeys made by connected cars and you’ll reprocess the same stream in different ways.
What is stream reprocessing?
Stream reprocessing refers to the process of re-analyzing or re-calculating data that has already been processed in a streaming architecture (where data is processed in real-time, as it is generated, rather than waiting to process it in large batches).
Data reprocessing is a common requirement in various contexts, such as A/B testing, debugging, reproducing production issues, or demonstrating the (re)processing of information. For example. suppose that you are taking an audio signal and smoothing it with a certain algorithm. Later, you come up with a better algorithm and want to reprocess the old data with your new algorithm.
Consumer groups and Offsets
To preprocess a stream with Kafka, you need to be familiar with the concept of consumer groups and offsets. While there’s not enough space to cover these concepts in detail, here’s a quick refresher.
- Consumer groups allow you to evenly distribute work to a group of consumers and control their behavior rather than configuring them individually. One use case is to reset the offset of a consumer group to replay or reprocess messages from a specific point in time.
- Offsets: These can be loosely compared to frame numbers in video editing software. An offset indicates the position of a message in a topic partition. They allow consumers to keep track of which messages have been read and where to start reading new messages from, and the “current offset” is similar to a “playhead” in a video track.
The following diagram uses the video track metaphor to illustrate how you can use a consumer group to:
1. rewind the “playhead” (current offset) to an earlier position in the topic (offset 20).
2. reprocess the same signal with a new algorithm.
3. append the reprocessed signal to a downstream topic that stores processed signals.

The nice thing about consumer groups is that you can have several of them reading from the same topic at different offsets. The following diagram illustrates two separate consumer groups doing just that.

The red consumer group has rewound to an earlier position in the topic, and the blue consumer group is processing the newest or “live” data from the topic—each consumer is also processing the data in different ways and writing to different topics.
This is useful if an application is latency-sensitive—both consumer processes can run in parallel with one handling live updates (low latency) and the other reprocessing historical data.
In this tutorial, I’ll focus on how to perform a simple rewind with a single consumer group, but if you want to learn more about consumer groups, see the article "What is a consumer group in Kafka? | Dev.to".
The scenario: reprocessing raw telemetry data from connected cars
In this tutorial, you’ll work with raw telemetry data collected from a variety of cars that have made test journeys through a city.
- Let’s say you have a research team who is interested analyzing the average distance traveled on historical journeys, and they use database queries to pull their reports.
- You have a streaming architecture that ingests the raw telemetry data and incrementally calculates the distance traveled for each vehicle.
- In your architecture, the total distance traveled for each car is periodically stored and updated in a database that your analysts use.
The problem
Originally, your distance calculation algorithm was writing the results to the database in miles, but someone pointed out that it should be in kilometers, so you fixed the code. But now, your database has distance measurements that are a mixture of miles and kilometers, and you’re not 100% sure which is which.
The solution
There are a number of ways to resolve this problem, but you can ensure that the data is clean by replaying all of the streams collected from the cars and updating the database so that it only contains kilometers.
Note: In real-life, use cases for stream replays are usually more complex than a misconfigured unit of measurement. For example, many teams use stream replays to reprocess data with an upgraded ML model. However, this example should be enough to give you an impression of how reprocessing works.
The setup
In this tutorial, you’ll run some Python programs that replicate this set up on your local computer.
The components are as follows:
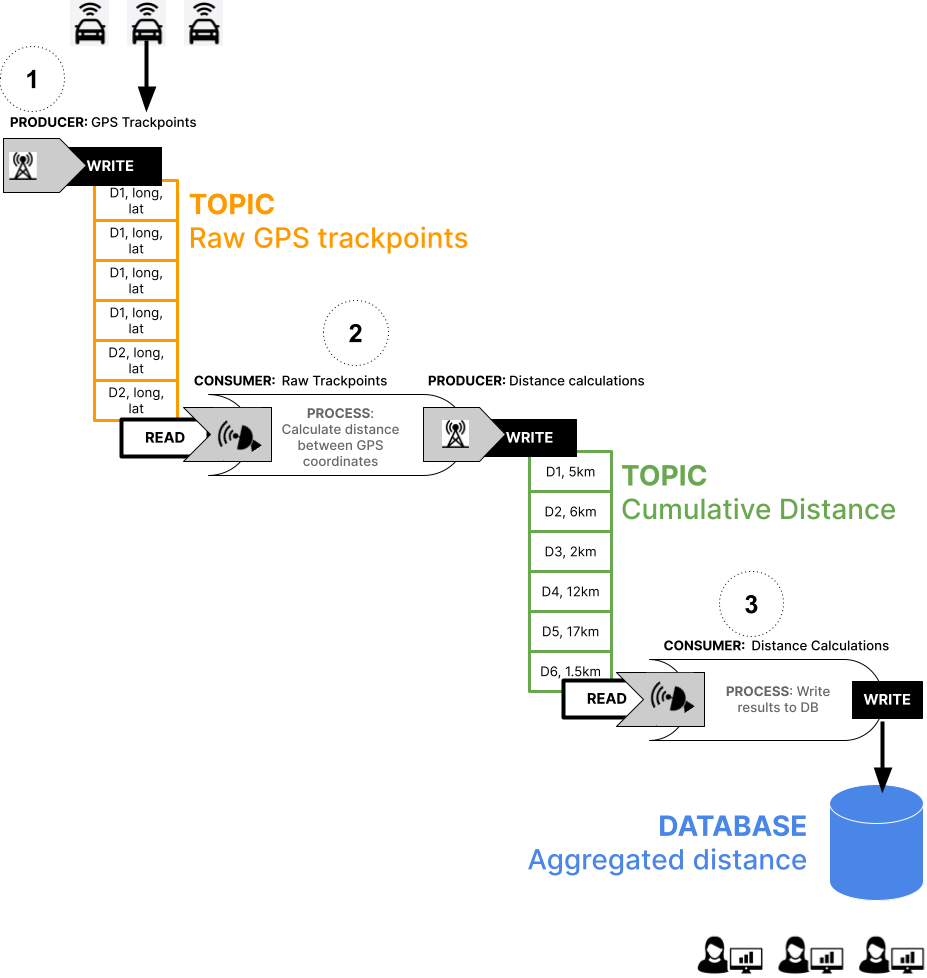
- 1_produce_trackpoints.py —a producer that sends GPS telemetry data to a raw_trackpoints Kafka topic
- 2_calculate_distance_miles.py —contains both consumer and producer functions.
—The consumer reads from the raw_trackpoints topic and processes the messages with a distance calculation algorithm.
—The producer takes the output of the algorithm and writes it to a second distance-calcs Kafka topic. - 3_write_distancestats.py —a consumer that reads from the calculations topic and writes the results into a database.
- 4_query_database.py —a script that queries the database (this is not a direct component of the streaming architecture).
The code for these components is in our tutorials repo which I’ll show you how to access in a moment.
However, I won’t be going through every detail of the code (the code itself also contains detailed code comments). The bulk of this tutorial will focus on helping you manage the process of replaying the streams and reprocessing the data.
Right, let’s try it out.
Getting the required components
As mentioned previously, this tutorial requires you to run various Python files from your terminal. These files are all in our tutorials repository.
- To get started, clone the repository and change to the tutorial directory with the following commands:
git clone https://github.com/quixio/tutorial-code.git cd reprocess-events
What you’ll need before you start
Before you can successfully run these files. you'll need the following to software to be installed:
The following libraries will be installed:
- Quix Streams: An open-source stream processing library that you’ll use to connect to Kafka and exchange messages as DataFrames.
- Pandas: Hopefully, Pandas needs no introduction—you’ll use it to process the DataFrames returned by the Quix Streams library.
- Geopy: a library used for geocoding and reverse geocoding, as well as calculating distances between two points on the Earth's surface.
- Tabulate: a library for creating formatted tables from data arrays or Python data structures such as dictionaries and lists.
- DuckDB: a simple but fast database that we’ll use to simulate a production database (which stores the reporting data that your stakeholders use).
Examining the Data
You’ll be using a subset of the GPS Trajectories Data Set that is hosted in the UCI Machine Learning Repository. We’ve created a CSV called go_track_trackspoints_sm.csv that contains a smaller subset of the data and included it in the repo you just cloned.
Here’s a preview of the first few lines:
| | id | latitude | longitude | track_id | time | |---:|-----:|-----------:|------------:|-----------:|:---------------| | 0 | 1 | -10.9393 | -37.0627 | 1 | 9/13/2014 7:24 | | 1 | 2 | -10.9393 | -37.0627 | 1 | 9/13/2014 7:24 | | 2 | 3 | -10.9393 | -37.0628 | 1 | 9/13/2014 7:24 | | 3 | 4 | -10.9392 | -37.0628 | 1 | 9/13/2014 7:24 | | 4 | 5 | -10.9389 | -37.0629 | 1 | 9/13/2014 7:24 |
Each track_id represents an individual car, and each row represents a track point recorded during each car’s journey (In reality, this data would come into Kafka through some kind of API Gateway as a continuous data stream).
- The original dataset includes approximately 163 unique track_ids, but to speed things up, our version only includes journey data for the first 10 track_ids (vehicles).
For this tutorial, let’s suppose that you’re working with an e-commerce application server that serves millions of users. To keep track of user activity, you’re using Nginx to log user sessions. However, with such high traffic volume, you’ve decided to use Kafka to collect and analyze log messages (formatted in JSON).
Let's get started!
Ingesting the GPS telemetry data
The first step is get the raw telemetry data into a Kafka topic for further processing. Later, you will rewind and replay the data in this topic again.
- To ingest the track points from the CSV into your Kafka, enter the following command in a new terminal window:
python 1_produce_trackpoints.py
This code uses the quixstreams library to automatically create a topic called raw_trackpoints and send each row as a DataFrame.
It should take a minute or so to send all the messages so you can move on to the next step while you wait. The last message should resemble the following example (id 889 is the last row in the dataset)
Sending Message: | | id | latitude | longitude | track_id | time | |----:|-----:|-----------:|------------:|-----------:|:---------------------------| | 680 | 889 | -10.8969 | -37.0535 | 14 | 2023-03-31 16:10:35.234497 | StreamID: device_14
Close the producer with CTRL+C.
Calculating the total distance traveled for each vehicle
Next, calculate the distance traveled for each vehicle in miles (which we’ll find out later is the wrong unit of measurement). This will send the calculations to a another downstream topic.
- To run the distance calculation algorithm, enter the following command in a second terminal window:
python 2_calculate_distance_miles.py
- This code uses the quixstreams library to create a consumer that reads from the raw_trackpoints, processes it with thegeopy library, and sends the calculations to a new distance_calcs topic
- The consumer is also configured to join a new consumer group called distance_calculator which helps to keep track of what data it has already consumed from the raw_trackpoints topic.
The last message in the stream should resemble the following example:
StreamID: device_13 publishing: | | id | track_id | distance | |---:|-----:|-----------:|-----------:| | 0 | 884 | 13 | 5.03135 | | 1 | 885 | 13 | 5.0871 | | 2 | 886 | 13 | 5.17075 | | 3 | 887 | 13 | 5.21673 | | 4 | 888 | 13 | 5.2218 |
- Again, close it with CTRL-C
Writing distance stats to a database
Now, you’ll run the code that consumes the distance calculations from the distance_calcs topic and writes them to a DB.
- To run the consumer that updates database, enter the following command in a third terminal window:
python 3_write_distancestats.py
The last message in the stream should resemble the following example:
Updating DB... Attempting to UPDATE dist_calc SET distance = 14.175262611932798 WHERE track_id = 13
After it has reached the end of the stream, stop the database writing process 3_write_distancestats.py by hitting “CTRL+C” or by closing the terminal window.
You’re closing the writing process so that you now can query the test database without getting an I/O error (this problem goes away if you use a production-grade database server).
Inspecting the calculation results in the database
Run the code that queries the “dist_calc” table in database.
- Enter the following command in an extra terminal window:
python 4_query_database.py
You can see that we now have the total miles traveled by device ID.
┌──────────┬──────────────┐ │ track_id │ distance │ │ int32 │ float │ ├──────────┼──────────────┤ │ 1 │ 4.7331457 │ │ 2 │ 9.325435 │ │ 3 │ 1.4511027 │ │ 4 │ 12.80555 │ │ 8 │ 0.75905204 │ │ 11 │ 4.7948756 │ │ 12 │ 1.0263699 │ │ 13 │ 14.175262 │ └──────────┴──────────────┘
Ok, so that’s the normal course of events. Now comes that part where you find out that you’re supposed to write the calculations in kilometers instead of miles.
Rewinding the stream
First of all, make sure that the distance calculation process 2_calculate_distance_miles.py is stopped by hitting “CTRL+C” or by closing the terminal window (it was the second one you opened).
You’re stopping the process because you can’t rewind a stream while a consumer group is still using it. The 2_calculate_distance_miles.py process belongs to the distance_calculator consumer group and we wont be able move the “playhead” for distance_calculator while it is still online.
Once you’ve stopped the distance calculation process, confirm where the consumer group left off by entering one of the following commands:
# Linux and MacOS bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --all-groups # Windows .\bin\windows\kafka-consumer-groups.bat --bootstrap-server localhost:9092 --describe --all-groups
Make sure you run these commands from within the Kafka installation directory.
You should see output that resembles the following example:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG distance_calculator raw-trackpoints 0 683 683 0
- Current-offset is where the playhead is currently located (akin to the current video frame).
- Log-end-offset is the total number of messages in a topic (akin to total video frames).
- Lag is the number of remaining unprocessed messages a in topic (akin to remaining video frames).
As you can see, the consumer group’s playhead is up to the last message in the raw-trackpoints, topic so we need to rewind it back to the beginning—offset 0.
To rewind the offset to the beginning of the raw-trackpoints , enter the one the following commands:
# Linux and MacOS bin/kafka-consumer-groups.sh --bootstrap-server 127.0.0.1:9092 --reset-offsets --group distance_calculator --topic raw-trackpoints --to-offset 0 --execute # Windows .\bin\windows\kafka-consumer-groups.bat --bootstrap-server 127.0.0.1:9092 --reset-offsets --group distance_calculator --topic raw-trackpoints --to-offset 0 --execute
Again, confirm that the consumer group’s playhead is now at the beginning of the raw-trackpoints topic by entering one of the following commands:
# Linx and MacOS bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --all-groups # Windows .\bin\windows\kafka-consumer-groups.bat --bootstrap-server localhost:9092 --describe --all-groups
You should see output that resembles the following example, where CURRENT-OFFSET is now 0.
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG distance_calculator raw-trackpoints 0 0 683 683
This means that any consumers who belong to the “distance_calculator” consumer group have to go back and read the from raw-trackpoints top from offset 0 again.
Updating the distance calculation and restarting the downstream functions
Now, you can start the corrected consumer process so that it can (re)consume the GPS stream and output the correct calculations.
- To run the corrected distance calculation, enter the following command:
python 2_calculate_distance_kms.py
This corrected process is also part of the same “distance_calculator” consumer group as the incorrect “miles” version.
Because you have told the “distance_calculator” consumer group to read raw-trackpoints from the beginning again, it will reprocess all the telemetry data, and send new messages to the dist-calc topic with the revised calculations.
Writing the corrected calculations to the database
Run the database write process again to process the new messages with the revised calculations:
python 3_write_distancestats.py
This consumer will begin reading the new messages that it has not yet seen and will update the aggregations in the database.
Inspecting the results of the database again
Again, after the database writing process has processed all the new messages, stop it again (to prevent I/O errors).
Then, run the database query command again:
python 4_query_database.py
┌──────────┬────────────┐ │ track_id │ distance │ │ int32 │ float │ ├──────────┼────────────┤ │ 1 │ 7.61726 │ │ 2 │ 15.0078335 │ │ 3 │ 2.3353236 │ │ 4 │ 20.608536 │ │ 8 │ 1.2215759 │ │ 11 │ 7.716604 │ │ 12 │ 1.6517822 │ │ 13 │ 22.812874 │ └──────────┴────────────┘
You can now see that the stats have been updated to kilometers. Congrats! You have just fixed the data in your database you now have the distance data in the required unit of measurement.
Recap
Phew, that was a lot and we didn’t look at what the code was doing! If you’ve made it this far, and everything went to plan, then kudos to you.
You've successfully learned how to build a simple streaming architecture, and learned the basics of reprocessing data in the source topic. You’ve used Python and Quix Streams to create producers and consumers, and you’ve reprocessed time series data to remedy an incorrectly configured algorithm.
By mastering these concepts and techniques, you've equipped yourself with valuable knowledge that can be applied to a wide variety of real-world problems, from IoT and telemetry data analysis to debugging issues and recovering from failures.
Now that you have a solid foundation in reprocessing streams with Apache Kafka, you can explore various ways to extend the project further. For example, you could:
- Inspect each of the code files you just ran, and read the code comments to get a more thorough understanding of what the producers and consumers are doing.
- Using one consumer group to keep reading the latest correct data, while you use another consumer group to fix a smaller section of the data (e.g. only data that was received during a specific time frame).
- Perform the same exercise with a stream from a real sensor, such as a Raspberry Pi with a DS18B20 temperature sensor
—Instead of a distance calculation you could calculate a rolling average of the temperature, and switch the units from Fahrenheit to Celsius.
—In this case you would still run Kafka on your PC, but connect to it from the Raspberry Pi using your PC’s IP address.
- Use the stream replay feature to test how different real-time machine learning models perform on the same stream of data.
The world of distributed systems is very complex but it can also be fascinating and empowering. Once you understand these basic concepts, you will have acquired a valuable and much sought-after skillset.
- If you encounter any difficulties with this tutorial or have any follow-up questions, feel free to reach out to me in the The Stream—our open Slack community for stream processing afficionados.
What’s a Rich Text element?
The rich text element allows you to create and format headings, paragraphs, blockquotes, images, and video all in one place instead of having to add and format them individually. Just double-click and easily create content.
Static and dynamic content editing
A rich text element can be used with static or dynamic content. For static content, just drop it into any page and begin editing. For dynamic content, add a rich text field to any collection and then connect a rich text element to that field in the settings panel. Voila!
How to customize formatting for each rich text
Headings, paragraphs, blockquotes, figures, images, and figure captions can all be styled after a class is added to the rich text element using the "When inside of" nested selector system.
Tomas Neubauer is Co-Founder and CTO at Quix, responsible for the direction of the company across the full technical stack, and working as a technical authority for the engineering team. He was previously Technical Lead at McLaren, where he led architecture uplift for Formula One racing real-time telemetry acquisition. He later led platform development outside motorsport, reusing the knowhow he gained from racing.
Check out the repo
Our Python client library is open source, and brings DataFrames and the Python ecosystem to stream processing.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.