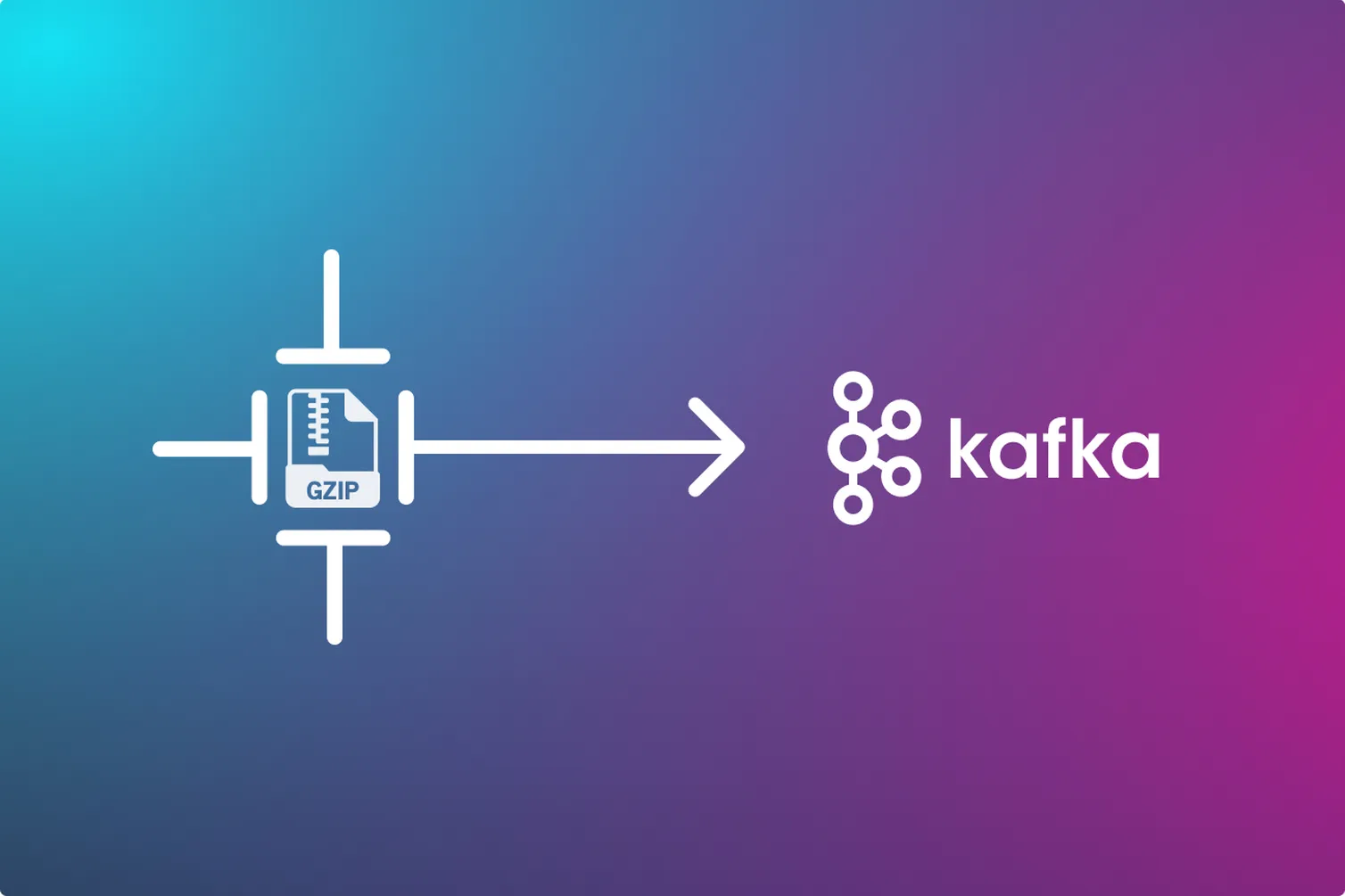
How to use gzip data compression with Apache Kafka and Python
Learn why data compression is vital and how use it with Kafka and kafka-python, focussing on gzip—one of the strongest compression tools that Kafka supports.



About this tutorial
One of the great things about Apache Kafka is its durability. It stores all published messages for a configurable amount of time, which means that it can serve as a log of all the data that has passed through the system. However, the downside is that Kafka’s storage requirements can be immense (depending on the volume of data you’re pumping through it). That’s why it’s important to think about message compression early on—and it’s why we’ve created this tutorial that focuses on compression.
What you’ll learn
By the end of this tutorial, you’ll understand:
- The different types of message compression supported by Kafka
- Why gzip is a popular choice and how you can use it to compress messages
- How to enable compression in different ways, at the topic level and in a Kafka producer, and the pros and cons of each.
- How to fine-tune the producer compression settings for even better compression.
- How to consume the compressed messages.
And you’ll learn how to do all of this in Python.
What you should know already
This article is intended for data scientists and engineers, so we’re assuming the following things about you:
- You know your way around Python.
- You’ve heard of Apache Kafka and know roughly what it’s for.
But don't worry if you don’t meet these criteria. This tutorial is simple enough to follow along, and we’ll briefly explain these technologies. Just be aware that it’s not intended for absolute beginners.
Why Is compression important when working with Kafka?
As mentioned in the introduction, Kafka needs lots of storage space—especially when you use its replication functionality. One way to reduce the amount of storage and network bandwidth you need is by using compression. This can be especially helpful when you're working with data that contains a lot of duplicated content, like server logs or XML and JSON files. However, it's important to note that compression can also increase CPU usage and message dispatch latency, so you need to use it with care.
Why choose gzip as a compression algorithm?
Because gzip provides the highest level of compression (with a few tradeoffs). To understand the different compression considerations, let’s compare all of the compression algorithms that Kafka supports.
Types of message compression in Kafka
Kafka supports the following options as compression types:
- gzip
- snappy
- lz4
- zstd
- none
"None" means no compression is applied and is the default compression type in Kafka. zstd compression is only available from Kafka version 2.1 onward.
The table below compares the characteristics of each compression type:
As you can see from the comparison, gzip achieves the highest compression possible, meaning less disk space utilization. However, gzip is also the most costly in terms of CPU utilization and takes the most time to compress. With that caveat in mind, let’s try it out and see what it can do.
But before you dive in, let’s get the prerequisites out the way. The following section shows you all the software you need to have installed before you can get started.
Prerequisites
The first thing you need is time—this tutorial should take about 45 minutes.
Also, before you proceed any further, make sure that you have the following software installed:
Major steps
Before we get into the details, let’s go over the major steps that we’ll be covering.
- Setting up Kafka: We’ll first get to grips with Kafka’s command line tools, and use them to:
— Start the Zookeeper and Kafka server.
— Create a topic (where we’ll be sending our data). - Downloading the data:
— Download the access logs from our storage server. - Trying different ways to enable compression:
— Create a Kafka topic with gzip compression
— Create a Python producer app with gzip compression - Sending data to a Kafka with a producer:
— Use the kafka-python library to read the log and send each line to Kafka. - Tuning the producer with configurations:
— Compare different settings and see how they affect the size of the compressed file. - Reading data from Kafka with a consumer
— See how easy it is to read it back in without any extra config
Implementing gzip compression in Kafka using Python
For this tutorial, let’s suppose that you’re working with an e-commerce application server that serves millions of users. To keep track of user activity, you’re using Nginx to log user sessions. However, with such high traffic volume, you’ve decided to use Kafka to collect and analyze log messages (formatted in JSON).
This problem is, your app generates a ton of logs, which can really eat up disk space and put a strain on network bandwidth. That's why you want to compress these logs to save space and make things easier on your network.
Let's get started!
Setting up Kafka
Before you can do anything with Kafka, you have to start the core services. Each of these services needs to run in a separate terminal window.
When following these instructions, start each terminal window in the directory where you extracted Kafka (for example “C:\Users\demo\Downloads\kafka_2.13-3.3.1\kafka_2.13-3.3.1”)
1. Start up your Kafka servers:
— In the Kafka directory, open a terminal window and start the zookeeper service with the following command:
- Linux / macOS
- Windows Powershell
You should see a bunch of log messages indicating the server started successfully. Leave the window open.
— Open a second terminal window and start a Kafka broker with the following command:
- Linux / macOS
- Windows Powershell
Again, you should see a bunch of log messages indicating the broker started successfully and connected to the Zookeeper server.
Also leave this window open.
Now that you have started these services, Kafka is ready to accept messages. Hopefully you’ve managed to do start them without any hassle. If you did, this troubleshooting guide might help
Downloading the data
Next, download the access.log file available under the resources directory of the GitHub repository. When extracted, this raw log file is approximately 14.5 MB and contains some sample Nginx access log records in JSON format. You'll use the producer app to stream this file's contents to the Kafka topic.
To prepare, follow these steps:
- Create a project folder (e.g. "kafka-gzip-tutorial”) and download the “access-log.tar.gz” file from this storage location into the project folder.
- If you prefer to use the command line, enter the following commands to create the project directory, then download and extract the file.
The “tar” command now works on now newer versions of Windows as well as Ubuntu and macOS.
You should now have the file ‘access.log” file in the root of your project directory.
Trying different ways to enable compression
In Kafka, there are a couple of ways to set it up gzip compression:
- On the topic level
If the term “topic” is unfamiliar, think of it as a process that maintains a log file that is constantly being updated. There are many ways to explain what a topic does in detail, but for now, let’s just say that it’s a process that logs events related to a specific type of data (such as, incoming transactions) including the data itself.
Kafka allows you to create a topic with any of the supported compression types so all the flowing through it gets automatically compressed. - On the producer level
You can also configure the producer code to send the data already compressed.
Which one to choose? It partly depends on where the system resources are allocated in your architecture.
- Compression requires lots of CPU, so compressing at the producer level might put a strain on the server that is hosting your producer process.
- On the other hand, sending uncompressed data through the network is going to eat up your bandwidth. If you’re in the cloud, this could cost you more in data transfer fees.
Thus, the answer depends on where you’re willing to make tradeoffs. In any case, you’ll be prepared, because you’re going to try both methods.
Enabling compression on the topic level
You’ll be using another of Kafka’s built-in scripts to create topics, so open another terminal window in the directory where you installed Kafka.
To enable compression on the topic-level, follow these steps:
1. Create a topic called “nginx-log-topic-compression”
— In a new terminal window, enter the following command.
- Linux / macOS
- Windows Powershell
Note that the command includes the config option --config compression.type=gzip--this creates the first topic with topic-level compression.
You should see the confirmation message “Created topic nginx-log-topic-compression”.
Confirm the topic's compressions type
To be extra sure that you created the topic with the right setting, you can run the describe command.
— In the same terminal window, enter the following command.
- Linux / macOS
- Windows Powershell
- You should see the console output that resembles the following example:
Note the Configs section, where it says compression.type=gzip.This tells you that the topic has been configured correctly.
Next, you’re going to create a second topic without any compression settings. This second topic will receive data that’s already compressed. The data will come from a producer that compresses the data before it is sent over the network. .
To create the second topic, follow this step:
— In the same terminal window and enter the following command.
- Linux / macOS
- Windows Powershell
By creating two topics, you can easily compare the different compression configurations. You’re going to compare the sizes of both topics to see which compression configuration is more effective.
Note: It might happen that you make a mistake during one of the procedures and want to recreate the topics from scratch. You can delete topics by using the simple (but brute force) method documented in this Stack Overflow answer. Then you can run the previous commands again to get fresh topics.
Now, let’s set up our producers.
Enabling compression at the producer level
You’ll using the kafka-python library to create a producer, so open your favorite Python IDE or code editor and follow these steps:
To enable compression on the producer-level, follow these steps:
1. In your project directory (i.e. “kafka-gzip-tutorial”), create a file called producer.py and insert the following code block:
view raw gzip_kafka_create_producer_1.py hosted with ❤ by GitHub
This code imports the required libraries and initializes the Kafka with a few options—the most important option for this step is compression_type="gzip" .
There are also two serialization options that serialize message keys and values into Byte arrays (Kafka expects data to be in bytes)
2. Save the file and keep it open.
For comparison, let's create a producer that sends standard uncompressed data (we’ll use it to send data to the topic with compression enabled).
To initialize a second producer without compression, follow this step:
- Underneath the code block for the first producer, add a second producer that doesn’t have compression enabled, like this:
view raw gzip_kafka_create_producer_2.py hosted with ❤ by GitHub
Setting up the producer to send data
Next, we’ll add the code that reads the data from the file and sends it to Kafka.
1. producer.py, add the following block underneath the existing code:
view raw gzip_kafka_create_producer_3.py hosted with ❤ by GitHub
Note that the code includes a switch to let you toggle between producers. It’s set to ‘topic’ because we’re going to try topic-level compression first.
After the file is opened, a ‘for’ loop:
- Reads the ‘access.log’ line-by-line.
- Serializes each batch into JSON and encoding the JSON as a Byte array
- Sends that JSON as a message to the selected Kafka topic
You can find a version of the complete file in our Github repository: https://github.com/quixio/tutorial-code/blob/main/use-gzip-compression-kafka/producer.py
2. Save your file and run your code with the following command: python producer.py
In your terminal window, you should start seeing confirmations like this:
“Sent record to topic at time 2022-12-28 13:23:52.125664” for each message sent
The producer will take between a few seconds and a few minutes to finish sending the messages to the topic.
Once the data is in the Kafka topic, it can be read by multiple consumers and extracted for more downstream processes.
3. Try the same procedure again, but this time with producer-level compression.
—Locate the line: "compmethod = 'topic'"
—Change the value from ‘topic’ to ‘producer’, so the final line looks like this: compmethod = 'producer'
—Run the code again with the command: python producer.py
Now, let’s find out what kind of difference the compression made.
Checking the reduction in log size
Earlier on, I described a topic as a “process that maintains log file”. Now it’s time to look at the actual size of that log file. Without compression, it will be at least as large as the original source file—which is14.5 MB. However, with gzip enabled, you would expect it to be smaller, so let’s take a look.
To inspect the size of the compressed log file, follow these steps:
1. In your Kafka installation directory, open a terminal window and enter the following command:
- Linux / macOS
- Windows Powershell
This command dumps the contents of the log file into a readable text format.
- You should see output containing lines similar to the one shown below
The string pattern compresscodec: gzip in the above code indicates that the messages are compressed and stored in the topic.
1. Get the file size with the following command:
- Linux / macOS
- Windows Powershell
Note that the file size might be displayed in bytes. If you want a more human-readable rendering of the file size, you can also navigate to the file location in Windows Explorer or the equivalent file manager on your operating system. Once you’ve identified the file size, you should see a significant size reduction.
- For example, when I ran the ‘du -sh’ command, the output was as follows:
3. Now, try the same procedure again but with the topic that stores data compressed by the producer.
- Do steps 1 and 2 again, but change the topic name from ‘nginx-log-topic-compression-0’ to ‘nginx-log-producer-compression-0’
You might notice that the producer-compressed data has a different file size, perhaps slightly higher than the topic-compressed data.
- For example, when I ran the ‘du -sh’ command, the output was as follows:
- Still decent compression, but about 1 MB larger than the log file compressed at the topic level.
So, does that mean topic level compression is better? Not necessarily. Compressing at the producer level gives you more freedom to tweak the settings and get even more compression. Let’s try that now.
Tuning the producer with configurations
When you ran producer-level compression just now, you didn’t add any of the optional arguments, which means you used the default compression settings.
However, you can also add arguments to configure settings such as batch_size and linger_ms.
- linger_ms controls the size of the message batches that the Kafka producer sends to the Kafka server. The producer waits until it has collected messages worth the specified batch_size before it sends them across the network.
- In general, more batching will improve the results of producer-level compression.
- When there are more messages in a batch, there is a greater likelihood that there are more identical data chunks that the Kafka producer can compress.hen there are more messages in a batch, there is a greater likelihood that there are more identical data chunks that the Kafka producer can compress
- linger_ms controls the maximum amount of time that Kafka is allowed to wait before sending the next message or batch of messages. The default is ‘0’ which means that the producer doesn’t wait at all. However, if you want the producer to create large message batches, you need to give it enough time to do so, which is why raising the waiting time is crucial for batching to work properly.
In general, you can think of these settings as two equally important thresholds. The Kafka producer will send a batch whenever one of the thresholds is met, and it doesn’t matter which one is met first.
- For example, if you have set a very high batch size, but haven’t given the producer enough time to “linger”, it will send a smaller batch than intended because the “linger” threshold elapsed first.
- On the other hand, if the producer has finished the specified batch before the linger time has elapsed, it will send the batch anyway. For this reason, you can be somewhat conservative with linger time—the producer won’t wait unnecessarily.
As a hands-on exercise, update your producer code with the extra batch_size and linger_ms arguments so that it matches the following example:
view raw gzip_kafka_create_producer_1a.py hosted with ❤ by GitHub
- Note: People using Macbook Pro with an M1 or M2 chip have reported issues with this part. After trying this revised code, they ended up with a kafka log of 0 bytes.
To make the comparison simpler, you will create a third topic to receive the data that has been compressed with the new settings.
To create a third comparison topic, follow this step:
In the same terminal window and enter the following command.
- Linux / macOS
view raw ml_kafka_create_producer_2.py hosted with ❤ by GitHub
- Note: People using Macbook Pro with an M1 or M2 chip have reported issues with this part. After trying this revised code, they ended up with a kafka log of 0 bytes.
To make the comparison simpler, you will create a third topic to receive the data that has been compressed with the new settings.
To create a third comparison topic, follow this step:
- Linux / macOS
- Windows Powershell
- Don’t forget to update the producer to write to the new topic. In producer.py, locate the following section:
view raw gzip_kafka_create_producer_3a.py hosted with ❤ by GitHub
Change the argument topic="nginx-log-producer-compression" to topic="nginx-log-producer-compressionv2". So that the section resembles the following example:
view raw gzip_kafka_create_producer_3b.py hosted with ❤ by GitHub
- Run the code again with the command: python producer.py
Then, repeat the procedure “Checking the Reduction in Log Size”, but do it for this third topic
Here’s the “DumpLogSegments” command again:
- Linux / macOS
- Windows Powershell
You should see a further reduction in file size
- For example, when I ran the ‘du -sh’ command, the output was as follows: follows:
The extra settings resulted in another 50% reduction in the file size! I got it down from 6.4 MB to 3.2 MB.
This shows how efficient producer-level compression can be when you configure it correctly.
Now, let’s look at how to consume the compressed messages. The process for consuming compressed messages is pretty much the same as it is for uncompressed messages, but it’s worth taking a look anyway.
Consuming the compressed messages
Now that you're done experimenting with producing compressed messages in Kafka, you can explore how to consume these messages.
To create a Kafka consumer, follow these steps:
1. In your project directory, create a file called consumer.py and insert the following code block to initialize the consumer.
- By default, Kafka consumers can decompress the messages from the Kafka topic without having to supply any configuration properties related to compression type.
- In the above code, the consumer instance of the KafkaConsumer class is not supplied with any properties related to compression type, but the process can still consume messages from the compressed topic.
2. Next, add the ‘for’ loop that will iterate through the messages and perform some processing on them.
view raw gzip_kafka_create_consumer_2.py hosted with ❤ by GitHub
- Decoding is done on the producer level.
- We selected the time parameter and used a method to render it as human readable.
- We also included the hostname and the address from the log entries.
3. Run the consumer app with the following command: python consumer.py
The output for the previous command should resemble the following example:
If you see the expected message output, well done! Congratulations for making it to the end.
Wrapping up
As you can see, Kafka’s built-in compression tools are great for conserving disk space and network bandwidth. Hopefully, you now have a better understanding of the different types of message compression Kafka supports and how effective gzip can be in particular. You learned different options for enabling compression, and how to fine-tune the level of compression at the producer level. Thus, you’re almost ready to wield your compression powers in production.
The main thing to remember is that gzip compression comes with increased latency and CPU utilization. Before you use it in production, make sure you test the different options and settings in an environment similar to the one you use for production. This includes testing it with production-sized workloads (for example, by replaying messages from another environment). You might get behavior that is significantly different from what you would get by testing on your local machine.
If you do use it in production, I hope that it works flawlessly on the first attempt (one can always dream right?). And if you are successful, I hope that this tutorial contributed in some small way. Happy compressing!
- You can find the relevant data and example code in this GitHub repository.
What’s a Rich Text element?
The rich text element allows you to create and format headings, paragraphs, blockquotes, images, and video all in one place instead of having to add and format them individually. Just double-click and easily create content.
Static and dynamic content editing
A rich text element can be used with static or dynamic content. For static content, just drop it into any page and begin editing. For dynamic content, add a rich text field to any collection and then connect a rich text element to that field in the settings panel. Voila!
How to customize formatting for each rich text
Headings, paragraphs, blockquotes, figures, images, and figure captions can all be styled after a class is added to the rich text element using the "When inside of" nested selector system.
Tomas Neubauer is Co-Founder and CTO at Quix, responsible for the direction of the company across the full technical stack, and working as a technical authority for the engineering team. He was previously Technical Lead at McLaren, where he led architecture uplift for Formula One racing real-time telemetry acquisition. He later led platform development outside motorsport, reusing the knowhow he gained from racing.
Check out the repo
Our Python client library is open source, and brings DataFrames and the Python ecosystem to stream processing.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.

Interested in Quix Cloud?
Take a look around and explore the features of our platform.