Core Architecture
The tabular data layer operates as an intermediary that decouples the logical view of data from its physical storage implementation:
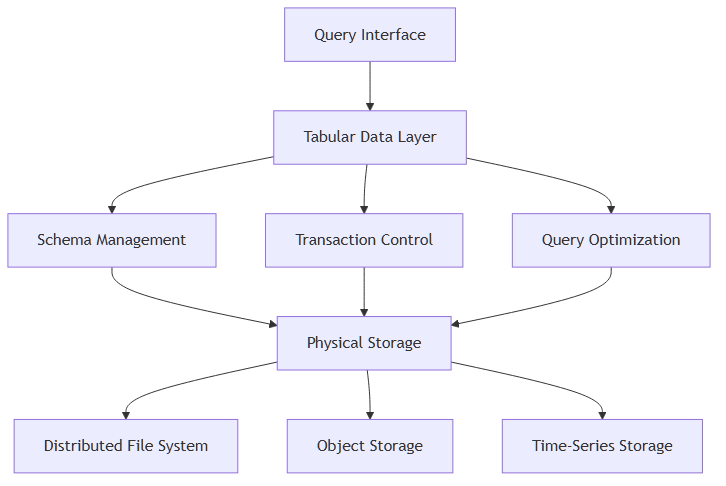
Key Functions
Schema Management
The layer enforces consistent schema definitions across distributed storage, ensuring that industrial data from different sources maintains structural integrity. This is crucial for maintaining data quality in data historians that collect information from various manufacturing systems and sensors.
Transaction Management
Provides ACID transaction capabilities that ensure data consistency during concurrent operations, essential for industrial environments where multiple systems may be reading and writing operational data simultaneously.
Query Optimization
Implements metadata-driven optimization techniques including predicate pushdown, partition pruning, and statistical query planning to improve performance when analyzing large volumes of industrial time-series data.
Data Organization
Manages the physical organization of data files, including partitioning strategies optimized for time-based queries common in industrial analytics and monitoring applications.
Applications in Industrial Environments
Manufacturing Data Integration
The tabular data layer enables seamless integration of data from diverse manufacturing systems, allowing engineers to query production data, quality metrics, and equipment telemetry using familiar SQL-like interfaces regardless of the underlying storage technology.
Simulation and Test Data Management
For organizations conducting extensive simulations and testing, the tabular data layer provides a unified view of results stored across different systems, enabling comprehensive analysis of design iterations and validation results.
Operational Intelligence
In industrial operations, the layer supports real-time and historical analysis of telemetry data from equipment, sensors, and control systems, facilitating predictive maintenance and operational optimization.
Implementation Considerations
Performance Optimization
The tabular data layer provides several performance benefits specifically valuable for industrial applications:
Integration Capabilities
Modern tabular data layers integrate with various components of industrial data ecosystems:
- Query engines like Apache Spark and Presto for distributed analytics
- Data catalogs for metadata management and data discovery
- ETL/ELT pipelines for data transformation and loading
- Business intelligence platforms for reporting and visualization
Best Practices
Performance Characteristics
The tabular data layer introduces some computational overhead compared to direct file access, but provides significant benefits in query performance and data management capabilities. The abstraction layer enables advanced optimizations that are particularly valuable for time-series workloads common in industrial applications, where data volumes can be substantial and query patterns are often time-based.
Popular implementations like Apache Iceberg, Delta Lake, and Apache Hudi offer enterprise-grade features including time travel queries, which are especially valuable for industrial applications requiring historical analysis and compliance auditing.