Core Components
Table formats consist of several essential elements that work together to provide robust data management:
Implementation Approaches
Copy-on-Write Strategy
This approach creates new files for any data modifications, providing immediate consistency and optimal performance for read-heavy workloads common in industrial analytics and reporting systems.
Merge-on-Read Strategy
This method maintains delta files that record changes, deferring data compaction until read time. This approach is better suited for write-heavy scenarios typical in real-time sensor data collection and telemetry data ingestion.
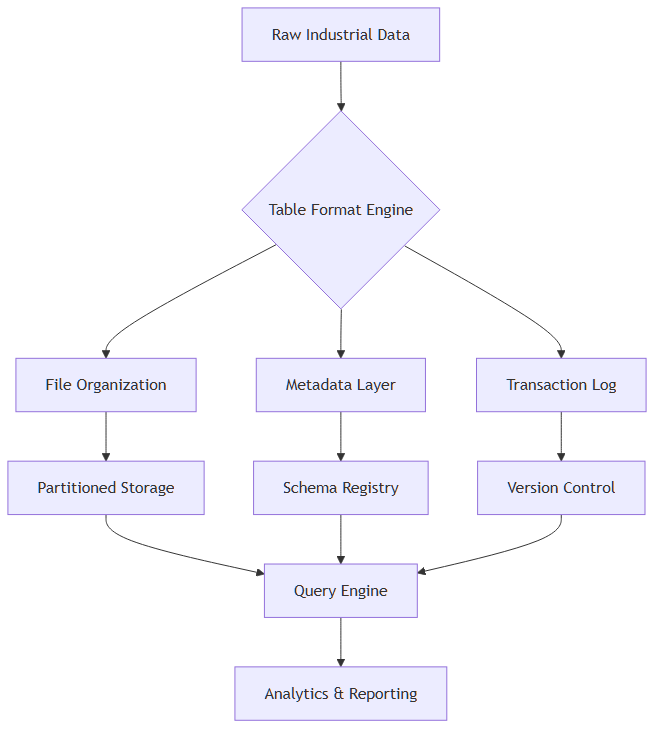
Applications in Industrial Environments
Industrial Data Management
Table formats are essential for managing massive datasets from manufacturing processes, where sensor readings, quality measurements, and operational parameters must be stored reliably with full traceability.
Model-Based Design Integration
In Model-Based Design workflows, table formats enable seamless integration between simulation results, experimental data, and production telemetry, maintaining consistency across the entire development lifecycle.
Distributed Testing Environments
For organizations running distributed testing across multiple facilities, table formats ensure that test results remain consistent and accessible regardless of the physical location of data storage.
Best Practices
Performance Considerations
Table formats introduce computational overhead compared to simple file formats, but provide significant benefits in data consistency and management capabilities. The choice between different table format implementations should consider factors such as query patterns, data volume growth, and integration requirements with existing industrial systems.
Modern table formats like Apache Iceberg, Delta Lake, and Apache Hudi offer advanced features such as time travel queries, which are particularly valuable for industrial applications requiring historical analysis and compliance auditing.