Core Sharding Concepts
Sharding distributes data across multiple database instances based on a predetermined partitioning strategy. Unlike vertical partitioning, which splits tables by columns, sharding splits data horizontally by rows, with each shard containing a subset of the complete dataset.
The fundamental components of a sharded system include:
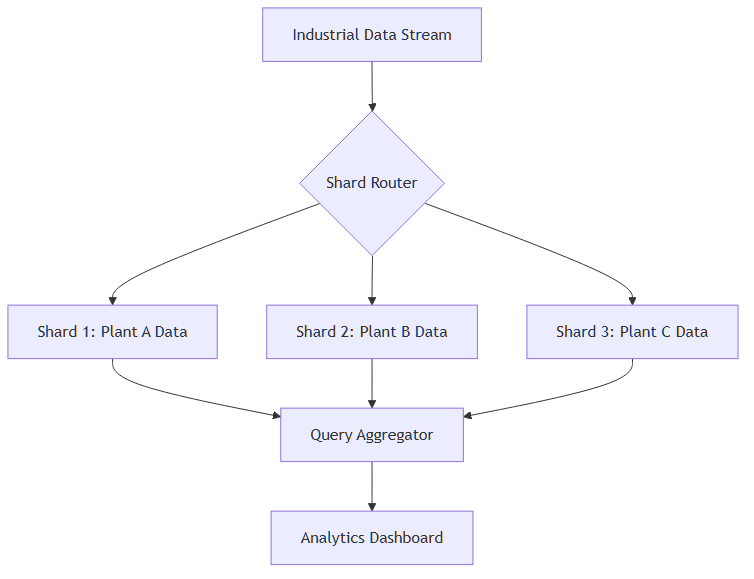
Sharding Strategies for Industrial Data
Time-Based Sharding
Industrial systems commonly use time-based sharding for sensor data, distributing records by timestamp ranges. This approach aligns with typical query patterns that focus on recent data or specific time periods.
# Example time-based shard key calculation
def get_shard_key(timestamp):
# Shard by month for historical analysis
return timestamp.strftime("%Y-%m")
# Route to appropriate shard
shard_id = hash(get_shard_key(sensor_reading.timestamp)) % num_shardsAsset-Based Sharding
Manufacturing environments benefit from sharding by production line, equipment group, or facility location. This approach keeps related sensor data co-located, improving query performance for asset-specific analysis.
Sensor Type Sharding
Complex industrial systems may shard by sensor type or data characteristics, separating high-frequency vibration data from low-frequency temperature readings to optimize storage and query strategies.
Implementation in Industrial Systems
Manufacturing Data Management
Large manufacturing operations generate massive amounts of sensor data across multiple facilities. Sharding enables distribution of data by facility, production line, or time period, allowing for efficient predictive maintenance analysis without overwhelming individual database instances.
Process Control Systems
Real-time process control benefits from sharding strategies that minimize cross-shard queries. Geographic or system-based sharding ensures that control algorithms can access relevant data quickly without network latency from remote shards.
Historical Data Analysis
Long-term trend analysis and regulatory compliance reporting require efficient access to historical data. Time-based sharding supports these requirements by enabling targeted queries against specific time ranges without scanning entire datasets.
Technical Considerations
Shard Key Selection
Choosing an effective shard key requires balancing several factors:
Performance Trade-offs
Sharding introduces both benefits and challenges:
- Write Performance: Improved throughput through parallel processing across shards
- Read Performance: Potential latency increase for cross-shard queries
- Operational Complexity: Additional infrastructure and monitoring requirements
- Data Consistency: Challenges in maintaining consistency across distributed shards
Best Practices for Industrial Environments
Operational Management
Effective shard management requires ongoing attention to performance monitoring, capacity planning, and system evolution. Industrial environments must consider maintenance windows, data migration procedures, and disaster recovery scenarios when implementing sharded architectures.
Sharding represents a powerful approach for scaling industrial data systems, enabling organizations to handle massive sensor data volumes while maintaining query performance and system reliability essential for modern manufacturing and process control applications.